

现代人工智能的方法过于零散,没有一个统一的框架,彼此之间的关系也模糊不清。《人工智能:一种现代方法》一书(Stuart Russell & Peter Norvig著,《Artificial Intelligence---A Modern Approach》, Prentice-Hall出版,2003第二版),试图用智能体Agent这一概念来统一描述人工智能的方法,但似乎并没有更好地揭示人工智能方法的本质。本文试图从计算机解决问题的过程本质出发,来建立一个框架,统一描述计算机解决问题的方法,进而揭示人工智能类方法的本质特征。
本文的基本思路是建立在计算机解决问题的基本模式之上的。计算机解决问题的基本模式可以概括如下:
实际问题----问题的逻辑计算化---解决问题的算法/知识---计算机程序---问题的解决结果。
围绕这个主线,可以逐步准确描述分解各个环节,从而将计算机应用问题做一个完整的框架性描述,看清每一种方法自己的定位,帮助理清各种方法彼此之间的关系等等。
多余的“人工智能”概念:计算机应用本就是智能过程
人类进入21世纪第二个十年之后,信息技术有了令人眼花缭乱的惊人发展。在许多“智能”方面已经超越了人类。但是,信息技术的基础一如其诞生之初,并没有改变。信息技术的核心计算机依然是,且仅是一个可编程的逻辑计算工具。只是今天它的计算能力与当初已经有了天壤之别,计算机在21世纪第二个十年具有了“暴力计算”能力(详见:谢耘著,《智能化未来——“暴力计算”开创的奇迹》第二章,机械工业出版社2018)。
计算机的基础——可编程逻辑计算能力算不算“智能”?对此很多人的看法是否定的。我们把识别图片作为理所当然的“智能”,而且为计算机能够识别复杂的图片而欢欣鼓舞,当作人工智能的一个重要的进步。而识别图片,是人类不需要特殊训练就具有的能力,但是逻辑计算却是人类需要一定的训练才能具备的技能。如果我们认为“智能”是人类大脑独有的功能属性的话,那么逻辑计算不被认为是“智能”,岂不是对人类大脑所做的努力的一种莫大的嘲讽?
所以,计算机最基本的能力——逻辑计算能力就是“智能”,或者说是一种智能活动,只是因为计算机一开始就以此为其存在的基础,我们无视了其智能的属性。从这个角度来看,计算机的应用其实都是智能类应用,只是“复杂”或“难易”程度有所不同而已。
正是由于人类没有理解自己创造出来的计算机与生俱来的可编程逻辑计算能力的智能本质,所以在1956年“人工智能”这个词被创造了出来,尽管当初、乃至至今人们也依然没有能力给它一个准确的科学范畴内的定义。提出“人工智能”这个概念的潜台词,便是用计算机实现的其它那些基于可编程逻辑计算的应用都不属于“智能”范畴。
当看明白计算机实现的可编程逻辑计算处理,在本质上就是“智能”活动,属于人类的“外意识”活动后(详见:谢耘,“信息技术的智能本质与人类的‘外意识’”,微信“慧影Cydow”公众号,2019年5月9日),我们不难发现,造出“人工智能”这个词,颇有画蛇添足的味道。尤其在“人工智能”概念存在了半个多世纪后,我们依然找不到它可以立足的科学基础原理、甚至也无法给“智能”下一个科学的定义的情况下,在科学与技术的范畴内,这个词就更显得有些多余。(详见:谢耘,“人工智能‘修炼成精’还是遥遥无期的梦想”,微信“慧影Cydow”公众号,2019年5月9日)
计算机解决问题的基本模式:用算法解决逻辑计算问题
虽然计算机的应用五花八门彼此迥异,但是计算机解决的所有问题的途径,都是通过逻辑计算来完成的。所以,所有的计算机应用都可以概括为下面几张图所示的一个基本模式。

首先,我们要对需要解决的不同领域的实际现实问题做分析,将其抽象转化为一个逻辑计算类问题(见图一),即可能用逻辑计算来解决的问题。这个过程通常是一个所谓的“数字化”或“建模”过程。
从这个角度讲,计算机应用的历程就是从容易抽象为逻辑计算类问题的实际问题开始,逐步拓展到去解决那些不太容易被抽象为逻辑计算类问题的实际问题的过程(详见《智能化未来—“暴力计算”开创的奇迹》第三章)。
计算机最开始的应用领域是工程/科学计算,这类问题基本不需要做抽象,本身就是逻辑计算类问题。而今天众多的所谓“人工智能”类问题则在表面上看起来与逻辑计算类问题很不一样,需要各种数字化与抽象建模的处理才能变成一个逻辑计算类问题。
将一个实际问题抽象映射为逻辑计算类问题之后,就开始进入了利用计算机来解决问题的阶段。这里分成两个基本的、并行相关的环节。
一个是这对这个逻辑计算类问题,设计出一个有效的、计算机可以实现的解决它的逻辑计算处理流程(也就是所谓的“算法”,其中包含了相关的知识),以此为基础形成解决问题的软件程序。所以一个软件程序就是某个“算法”的具体表现形式;另外就是要准备好解决问题所需要的信息/数据,形成程序所需要的输入。
在此基础上,计算机就可以利用自己的逻辑计算能力,在软件程序,也就是人类的“外意识”的控制下完成对输入数据的处理,给出问题的答案(见图二)。
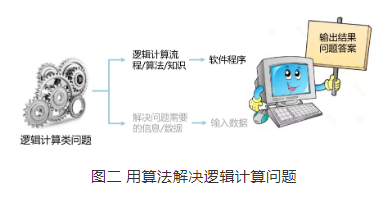
显而易见,针对不同的问题,软件程序包含了不同的知识,实现的是不同的算法流程。虽然不同的算法与知识在复杂程度上有很大的差异,但是这些软件程序却都是人类的“外意识”,同属于智能类活动。就像博士生动脑子是人类的智能活动,小学生动脑子同样也属于人类的智能活动。
如果考虑到实际发生的情况,图二中解决问题所使用的算法,有时不是一个单向的过程,而是会有多次的反复“迭代”修改完善的复杂环节在其中,而这个过程通常要借助系统的输出结果中的信息来进行,所以实际上这种情况是一个在实践中不断完善的“反馈”过程。如果把这个反馈优化完善的过程显性地表现出来,图二就演变变成了图三。
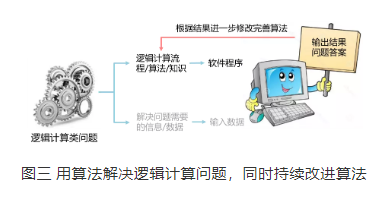
我们不难看出,图二的模式与图三模式是等价的,图三只是把解决问题的算法中根据结果做反馈改进的步骤显性地表现了出来而已。当然,图三中的反馈过程也可能是由人来完成的,这就是在我们讨论之外的情况了。
对于从图一到图二所示的计算机解决问题的一般模式,我们可以做如下的一个概括:任何一个问题,只有把它变成逻辑计算类问题,计算机才有可能解决它;反过来,计算机解决任何问题,都是通过逻辑计算过程来完成的。
所以,当我们好奇计算机是否能够做某件事情时,我们首先要做的就是去看看我们是否有可能把这件事变成一个逻辑计算类问题。
当然,并不是把一个实际问题转化为逻辑计算类问题,就必定能够找到一个有效的算法去解决它。这个寻找有效解决问题“算法”的过程,是没有一个绝对可行的方法论可以依靠的。它至今依然是一个严重依赖人的大脑的创造性工作,而且在可以预见的未来,依然会如此。
所以计算机自动编程,也就是计算机自动寻找并实现解决问题的有效算法,还是一个遥远的梦想。
但是这并不意味着计算机在寻找和设计解决问题的算法的工作中就无所作为。“机器学习”就是人类借助计算机来寻找解决问题所需算法的技术。
“机器学习”(Machine Learning)方法的本质:用“学习算法”去帮助最终确定完善解决问题的算法
记得有一个国际人工智能界的名人曾经说过一句话:“人工智能就是机器学习,机器学习就是人工智能。”所以,如果我们能够搞清楚“机器学习”的本质,也就理解了“人工智能”到底是什么了。那么我们就来看一下“机器学习”这个听上去高深莫测的技术,在本质上是一个什么样的过程。
既然“机器学习”也是由计算机完成的工作,所以它必然也没有跳出图一到图三所概括的计算机应用的基本模式。因为“机器学习”是一个寻找算法的过程,与图一关系不大,所以我们从图二来开始分析。
对于一个逻辑计算类问题,如果我们能够找到一个有效的算法,显然就不需要什么“机器学习”来帮忙,直接按照算法编个程序问题就解决了;反过来,如果针对一个逻辑计算类问题,我们完全摸不到头脑,不知道去任何方向来寻找解决它的算法,那么“机器学习”也没有任何用途。
“机器学习”有用武之地的场合,是针对那些逻辑计算类问题,我们不知道哪个完整的算法能够解决它,我们却知道有某个“类型”的算法(比如求解某个函数)可以解决或可能解决它,但是我们需要想办法确定算法的中的一些成分(比如函数中的参数)才能完全把算法明确下来,然后用它去尝试解决这些问题。
比如,我们想确定一个火炮的具体位置,我们知道它发出的炮弹的弹道在不考虑空气阻力等因素下可以用一个二次方程来描述(抛物线),如果知道了这个二次方程,我们就能用二次方程求解的算法来确定火炮的位置。但是我们事先是不知道这个火炮发出的炮弹轨迹的二次方程里的三个参数的,这三个参数就是我们解决问题需要的算法(二次方程求解算法)中的“成分”。如果我们有办法确定这三个参数,那么解决问题的算法就确定了。
所以,在这个例子中,确定火炮位置的问题,是一个二次方程求解类的问题,可以用二次方程求解算法来解决,但是我们需要知道炮弹弹道二次方程的三个系数,才能最后确定算法。确定这三个参数,就是机器学习要做的事情。
所谓“机器学习”,就是利用计算机帮助我们确定解决问题的(可能的)算法中的细节,通常就是算法中所需要的某些“参数”。
所以,“机器学习”在解决问题的过程中,是在辅助人类,而不是独立自主地去解决那些我们人类都完全不知道该从何入手的问题。
那么“机器学习”是如何确定我们需要的算法中的“细节”或称“参数”的呢?
我们需要一个所谓的“学习”算法,然后用它从所谓的“学习样本数据”,即那些可以从中获取我们需要的“细节”或称“参数”的数据/信息,估算出我们需要的“细节”或“参数”,然后我们就可以确定解决原本问题的算法了,问题便迎刃而解。
将上述过程用图来表示,就得到下面的图四。

从图四中我们可以看出,用“机器学习”的方法来解决问题的时候,相比于图二,看上去它多了一个“机器学习(训练)”的过程,即获取解决问题的算法所需要的参数的过程。
这个机器学习的过程,本质上也是图二所示的计算机解决问题的过程,即也是用逻辑计算算法(所谓的学习算法)来达到目标(估计解决问题的算法所需要的参数)的一个过程。
而由于只要不导致算法不收敛等问题,多种“算法”可以组合嵌套组合成一个更复杂的算法,所以图四中上面的学习算法实际上是可以合并到图中下面解决问题的算法当中的,它所需要的学习样本数据也可以当作“解决问题需要的信息/数据”的一部分,这样合并之后,图四则被抽象简化变成了图二,或者说图四其实是图二的一种具体情况。
所以,用“机器学习”的方法去解决问题,在本质上依然归属于图二所示的计算机解决问题的基本模式,而不是独立于其外的全新做法。因此,它依然要依靠人来设计“算法”去解决问题,这个过程依然是“外意识”发挥作用的过程。在这个过程中,人或者说人的“内意识”对于需要解决问题的深刻理解,依然是一切的源头起点。
我们以前面讲过的确定火炮位置的问题为例,来看一下一个机器学习的具体过程。

在战斗中,我们希望通过A火炮发射的炮弹的轨迹,来确定其位置将其消灭掉。在不考虑空气阻力、风向等因素的情况下,我们知道它发射的炮弹的轨迹是由一个二次方程来确定的曲线。但是我们没有办法事先就知道这个方程中的三个参数,所以我们通过“火炮侦校定位雷达”,来获取它发射的炮弹的轨迹中的一部分数据,这就是所谓的“学习样本数据”。利用这部分数据,我们就可以利用计算机估算出来描述炮弹轨迹的二次方程中的三个系数。这样就完成了图四中“‘机器学习’过程”。然后我们通过利用计算机求解这个方程。就能够确定A火炮的位置,这就是图四中的“解决问题过程”。B火炮便可以依据这个位置信息摧毁A火炮。
虽然实际情况要更复杂一些,考虑大气阻力等因素后炮弹轨迹要用更高阶方程来描述,而且是在三维空间,因此会有更多的参数需要确定,但是上述的基本原则是一样的。
这个例子虽然看上去很简单,有中学的知识就完全可以理解,但是它确实就是机器学习方法中的一种。这种机器学习的方法就是所谓的“回归分析”方法中的多项式回归分析(赵卫红、董亮编著,《机器学习》,第18页,人民邮电出版社,2018年8月第一版)。而这些年流行的“深度学习”,则是采用了非常高阶而复杂的函数。函数复杂到了很难用一个数学表达式来描述,而是采用了一种网络化的描述方式。在用于解决问题的这种复杂高阶函数中,有成百上千万,甚至上亿个参数需要用机器学习的算法来确定。所谓“深度学习”中的“深度”,指的就是这些参数的数量的巨大,并非是我们通常意义上学习的“深度”。
如果图四中上面所示的机器学习过程与图中下面的解决问题过程彼此独立,我们称这种情况的机器学习为“离线”机器学习。这里的“线”指的就是图中下面那个解决问题的过程。
如果机器学习需要的学习样本数据来自于解决问题的过程的输出结果,这样的机器学习我们称之为“在线”机器学习,这个过程就是图三所示的反馈优化完善的过程。我们把机器学习过程拆分出来,便得到了图六。
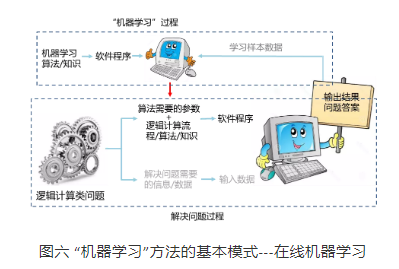
我们不难看出,图六也可以看作是图四的一个特殊情况,即“学习样本数据”来自“解决问题过程”的输出。不论对图六作何种解读,它也都可以归入图二所示的计算机解决问题的基本模式。
通过上面的分析我们能够看出,如果把“机器学习”方法与“常规”的方法相比较,它们的差别就在于在常规方法中,解决问题的算法是事先就确定的,而在“机器学习”方法中,解决问题的算法有未知的成分,需要另外用某种“机器学习”算法来估算出这些未知的成分(通常表现为“参数”),然后才能形成完整的解决问题的算法去解决问题。但是这个差异却并不能否定它们之间本质的共性,即归根结底,机器学习方法也罢,常规方法也罢,不过都是利用计算机通过计算机可以实现的逻辑计算的算法,去解决逻辑计算问题的过程。都离不开人对于问题的理解以及在此基础上设计出来的算法去解决问题。所以,图一与图二是对计算机解决问题模式的基本概括,而后面几张图是这种概括在具体情况下的展开表达。
机器学习方法的“工匠”特征
机器学习方法相当庞杂,并非是像数学或物理学那样,建立在几个基本公理/定律之上。不同方法有不同的来源,有不同的长短。针对一个实际的问题,把它变成哪种类型的逻辑计算问题,用哪种机器学习的方法能够有效的解决,是没有一定之规的,这与传统的经典科学技术领域有很大的不同。
这个过程,既依赖对不同机器学习方法的理解和已有的相关经验,还需要大量的反复尝试。所以这是一种“现代工匠”类型的工作。
我们以机器学习中的著名的深度学习为例来看一下其工匠性质。在《深度学习》(【美】伊恩·古德费洛等著,MIT Press出版,2016年)这本被认为是“深度学习”领域奠基性的经典教材中,作者为了阐述深度学习的这种实验性工匠特征,专门在第二部分设置第11章来讨论这个问题,它的题目取为“实践方法论”。在这一章的开头,作者写了这样一段话:“要成功地使用深度学习技术,仅仅知道存在哪些算法和解释它们为何有效的原理是不够的。一个优秀的机器学习实践者还需要知道如何针对具体应用挑选一个合适的算法以及如何监控,并根据实验反馈改进机器学习系统。在机器学习系统的日常开发中,实践者需要决定是否收集更多的数据、增加或减少模型容量、添加或删除正则化项、改进模型的优化、改进模型的近似推断或调整模型的软件实现。尝试这些操作都需要大量时间,因此确定正确的做法而不盲目猜测尤为重要。”这段话比较完整地揭示了深度学习这个具体技术的“现代工匠”特征。
纽约大学教授Gary Marcus在2018年1月2日发表的引起很大争议的文章“Deep Learning: A Critical Appraisal”(arXiv.org,2018年1月2日)中提出了深度学习的十个局限,其中第十个“Deep learning thus far is difficult to engineerwith”指的也是这个问题——“深度学习”还只是一个就事论事的方法,没有办法作为一个标准普适的有效的工程方法被用来去有效地解决不同的问题。换句话来说,以深度学习为代表的机器学习法,是一种现代的工匠技艺,而不是其它领域中现代工程师使用的、有坚实现代科技基础的工程化普适方法。(谢耘,“‘深度学习’与工匠技艺”,微信公众号“慧影Cydow”,2018年3月22日)
其实这个问题并非是机器学习所独有,而是作为人类“外意识”的计算机应用的基本特征。其根源便在于人类迄今为止,没有构建出关于人类意识活动的完整的科学理论,只有一些实验性质的描述与推测,所以当我们把人类的意识外化为计算机应用的时候,它在总体上就只能是一种基于工匠技艺的手艺活。早就有人指出软件编程是一种艺术创造过程,原因也在于此。由此也带来了一个问题:算法自身的复杂程度,并不能代表其技术水平的高低,因为艺术性的创造,是可以为所欲为的。
在人类突破意识活动(或称智能)的科学原理之前,计算机应用、即人类的“外意识”的创造活动,在总体上只能是一种八仙过海式的现代工匠技艺。
终极追问
在业界不断有消息声称某机器学习已经实现了“问题”无关性,即算法不需要借助人类对问题的理解即可以自己学习解决问题。这显然是有意夸大其词,或者算法的设计者自己无视了他在设计算法时带入的对问题的理解及相关的知识。通过前面的分析,我们可以得到机器学习与人的学习之间的差异。

表一 机器学习与人的学习的对比
在人类突破意识活动(或称智能)的科学原理之前,我们不可能设计出一个与问题无关的万能算法,让机器自己去独立从零开始学习而解决不同的问题。计算机修炼成精还是遥远的梦想。(谢耘,“人工智能‘修炼成精’还是遥遥无期的梦想”,微信公众号“慧影Cydow”,2019年5月9日)
但是这并不意味着在解决具体问题上,机器学习不会比人强。其实,自计算机诞生伊始,它在逻辑计算方面的能力就远非人类可比。借助计算机不断增强的精确且永不疲倦的“暴力计算”能力,机器学习方法在解决各种具体的问题方面,自然会不断超越人类。而这正是人类创造工具的重要的目的:拓展人类的能力边界。
人与工具之间的这种辩证的互补关系,常常被形而上学地解释成为了机械的对立互斥替代关系,以至于从工业革命开始后,就不断出现各种版本的机器将取代人的耸人听闻的“预测”。
计算机在解决各种具体问题方面不断超越人,这根本就不是什么预料之外的“奇迹”。今天的机器学习、人工智能及大数据技术核心采用的都是数学统计方法。而早在1964年,英国出版的近代数学通俗读物《统计世界》一书,作者就数学统计方法的应用前景在最后的“回顾和展望”中写道:“在今天的世界上,统计方法的新应用正在不断地被发现,应用电子计算机进行计算,使科学家能够解决过去认为不可能解决的统计问题。统计方法的应用将继续扩大,统计学将在未来的空间时代发挥重要作用。”(【英】D.A. 约翰逊、W.H.格伦著,《统计世界》,第80-81页,科学出版社,1981年)

图七 1964年的“神预测”
书中的这段话算是对今天以数学统计方法为核心的大数据、人工智能技术发展的“神预测”吗?其实这只是掌握了科学技术本质的科学家对未来的一种理性的推断。
来自网络的图八,形象地表达了数学统计方法、机器学习及人工智能之间的关系,并巧妙地暗示了产生人工智能“奇迹”效应的社会心理缘由。

图八 统计方法、机器学习与人工智能
对于今天我们强烈依赖数学统计及工匠式的方法来解决问题,很多习惯于经典科学方法的人内心会感到不适。2018年我在山东大学给学生做讲座时讲了机器学习与人工智能的本质。当时一个同学在提问时说:“我不喜欢现在的那些人工智能的方法,它们都是统计实验性质的,不像经典科学方法那样清晰严谨精美。”我对他说:“技术是用来解决问题的手段,而不是拿来欣赏的艺术品。只要能解决问题就是有效的方法,就应该去认真学习。”
来源: 图灵人工智能