如果你在一条道路上行驶,突然前面拐弯处出现一辆无人驾驶汽车,你会继续坚持你的道路优先权,还是让位使它先过去?目前,我们大多数人在涉及其他人的情况下能表现出友善的一面,但对自动驾驶汽车能否表现出同等的善意不得而知。使用行为博弈论的方法,来自慕尼黑大学和伦敦大学的一个国际研究小组进行了规模化的分析研究,以了解人们是否会像人工智能(AI)那样与其他人类平等合作,这项发表在 iScience 杂志上的研究发现,早期,人们对 AI 的信任程度与人类相同:大多数人都希望遇到愿意合作的对象。区别就在后续,人们倾向于利用它为自己谋利。回到交通示例,人类驾驶员可能会礼让另一个人类驾驶员,但不太愿意礼让自动驾驶汽车,这项研究将这种不愿与机器妥协的态度,视为未来人类与 AI 交互的一种新挑战,这个漏洞不仅需要更智能的机器,而且需要更好的以人为中心的策略。“人们期望 AI 能像真的人类一样友好合作。然而,他们并没有回报那么多的仁爱,对 AI 的利用成分要比人类多。”Jurgis Karpus 博士解释说,他是行为博弈论专家,慕尼黑大学哲学家,也是这项研究的第一作者。Jurgis Karpus 表示:“算法开发会带来进一步的后果。如果在路上人类不愿意礼让一辆有礼貌的自动驾驶汽车,那么自动驾驶汽车是否应该为了高效率而少一些礼貌,多一些进击性?”
合作与利用设想(来源:iScience)4 个游戏与 2 个假设随着 AI 代理逐渐获得自主决策的能力,人类未来将与它们一起工作或并肩决策。过去几年,在国际象棋、围棋和星际争霸等游戏领域,AI 的表现已经超过人类,但在日常社交互动情况下,大多不是零和游戏,不是一方赢了,另一方就输了,相反,需要通过 AI 与人类合作实现最终互利。而谈及合作,往往涉及妥协和风险:一个人可能不得不为了集团利益而牺牲一些个人利益,并使自己面临其他人可能不合作的风险。经济博弈是检验人们合作性的有效工具,最近的一些业内研究表明,当由两个或两个以上人类决策者组成的群体面临集体问题时,几个机器人的存在有助于人机群体中人类之间的协调与合作,然而,这并不意味着人类愿意与人工智能体进行一对一的合作。人们对机器的回馈往往比对人的回馈要少,更重要的是,在社交互动环境中人类减少与机器合作的原因仍然无法解释,有时候,一旦人类知道他们在与机器互动,合作关系就会崩溃。人们似乎不信任预测算法和人工智能在复杂决策任务中协调行动的能力。于是,研究人员提出了两种假设:第一种假设(H1)关注于 “预期”,当合作可以带来互利,但由于对方可能自私而不合作具有风险时,人类 “预测” 与 AI 的合作可能将比与人类的合作要更少。第二个假设(H2)侧重于 “算法利用”:当人们期望与另一方合作时,如果对方是 AI 代理,他们会比另一方是人类时更倾向于利用对方的仁慈,如果把这个假设推到一个极端,H2 将预测人类将毫无顾忌地利用那些能合作但没有知觉的人工智能。为了测试和澄清一个或两个假设是否成立,研究人员通过四个著名的一次性游戏进行了测试,分别为:信任游戏(Trust)、囚徒困境(Prisoner’s Dilemma)、胆小鬼博弈(Chicken)和猎鹿博弈(Stag Hunt),共进行了 9 个实验。
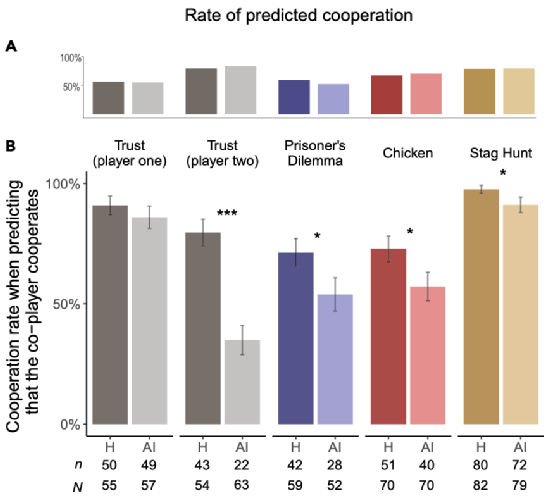
当人们看到利用 AI 的机会时,与 AI 的合作成分就变少了(来源:iScience)人类更热衷于利用 AI当人们被告知正在与 AI 代理或匿名人类互动时,分别会有什么反应呢?研究人员进行了一番统计分析。在实验 1 中,403 名参与者参与了信任游戏,每个参与者被分配到游戏中第一个或第二个玩家的角色,并面对一个人或一个 AI 代理作为合作者。如果第一个玩家合作,第二个玩家就可以决定游戏的最终结果。第二个玩家决定叛逃(play*)对她自己有利,而合作(play+)对两个玩家都有利。因此,只有在第一个玩家期望第二个玩家以实物回应的情况下,合作才是值得的,但是,由于个人回报可能更高的前景,会诱使第二个玩家叛逃,因此合作对第一个玩家来说是有风险的。通过实验,研究人员得出了第一个结果:当人类与人类互动时,扮演一号角色的大多数参与者(74%)会选择合作,扮演二号角色的大多数参与者(75%)会做出类似的反应。而在与 AI 代理的互动中,扮演玩家一角色的大多数参与者(78%)也选择了合作。然而,在扮演第二角色的参与者中,与 AI 代理的合作率(34%)会显著低于与人类的合作率。尽管在选择行为上存在差异,但人们对人类和 AI 合作者决策的期望是相同的:79% 的参与者希望有一个人类合作者合作,83% 的参与者希望有一个 AI 代理来合作。这些结果支持假设 H2 而不是 H1:人们期望 AI 代理与人类一样可合作或仁慈,但如果有机会,他们更愿意利用仁慈的 AI 代理,而不是利用仁慈的人类。那么,在参与者之间更为对称的风险分配是否会对恢复队等合作有帮助?为了测试这一点,研究人员又分别进行了实验 2 和实验 3,其中 201 名参与者玩囚徒困境游戏,204 名参与者玩胆小鬼博弈游戏。结果发现:当人们与人类互动时,一半的参与者(49%)在囚徒困境中会合作,大多数参与者(69%)在胆小鬼博弈中会合作。当与人工智能代理互动时,两种游戏中的合作率都显著降低:囚徒困境中的合作率降为 36%,而胆小鬼博弈中的合作率则为 56%。尽管在选择行为上存在差异,但人们对人类和 AI 合作者决策的预期是可比的。在囚徒困境中,59% 的参与者期望他们的合作者是人类,52% 的参与者期望与 AI 代理合作;在胆小鬼博弈游戏中,67% 的人希望得到人类的合作,70% 的人希望得到 AI 代理的合作。在那些期望自己的合作者能够很好合作的参与者中,与 AI 代理的合作率在囚徒困境中为 54%,在胆小鬼博弈中为 57%,明显低于与人类的合作率(分别为 71% 和 73%)。这些结果也支持 H2 假设,但不支持 H1 假设,并将先前的研究结果扩展到具有对称分布风险的游戏:当合作者是 AI 代理时,人们更热衷于利用其预期的仁慈。在实验 4 中,205 名参与者参加了猎鹿博弈,结果显示,当人们与人类互动时,大多数参与者(86%)会合作,与 AI 代理的合作率(80%)也无显著性差异。研究人员观察到,人们减少与 AI 合作的主要原因并不是为了超越机器而进行的激烈竞争。当单方叛逃没有什么好处时,人们也愿意冒险与 AI 代理合作,就像与人类合作一样,以达到互利的结果。当参与者与 AI 代理互动时,他们更可能出于私利而这样做,相反,当他们与人类互动时,他们更可能出于共同利益而合作。这表明,即使人们与 AI 代理合作的可能性和与人类合作的可能性一样大,但合作动机却不同。除了这 4 项实验,研究人员还补充进行了实验 5-8 和实验 9,结果都比较吻合 H2 的假设。有待进一步改进的 AI 法则研究人员表示,这些测试结果为重新思考人类和 AI 之间的社会互动提供了新的依据,也提出了一个新的道德警示。时至今日,大多数关于 AI 的警告,都集中在它们可能恶意以及可能不公平对待人类的风险上,因此,目前的政策旨在确保 AI 单方面会公平地为人类谋利益。2017 年制定的《阿西洛玛人工智能原则》(Asilomar AI principles)得到了来自人工智能、政治、商业和学术界的 3700 多名专家的认可,例如,该原则建议 “人工智能研究的目标不应是创造无向智能,而应是创造有益的智能”。同样,欧盟委员会也将公平视为人工智能必须遵守的四项道德要求之一。然而,在本项研究中,研究人员的发现补充了一个不同的警告:如果工业界和立法者公开宣布人工智能在默认情况下是仁慈的,人类就可以更容易地决定利用它的合作性。因此,拥有无条件服从和合作的机器,可能无法使我们未来与人工智能的互动更加道德和互利。这就指向了当前 AI 政策讨论中的一个盲点:如果想将 AI 融入人类社会,需要重新思考人类将如何与它们互动。此外,先进 AI 算法开发需要更大规模的研究,AI 代理会基于先前对人与人之间社会互动观察来模拟人类行为,随着时间的推移,机器能够使用自己与人类交互的数据:如果 AI 学会人类对于合作的区别对待,AI 最终可能也可能会减少与人类的对等合作。在这种情况下,出现错误不在于我们的算法,而可能在于我们自己。关于此项研究的局限性,研究人员表示,需要进一步研究人类与人工智能之间的合作,才能将研究结果外推到经济博弈之外的现实世界中,目前的研究结果旨在为进一步研究人工智能与人的交互作用提供概念证明。进一步探索的一个途径是,当 AI 代理的行为直接有利于或伤害其他人时,人类愿意与 AI 代理合作,而 AI 代理可能代表着其他人的利益。另外,研究人员观察到,算法开发是在这样一种环境下进行的:即 AI 赚取的分数被转换成钱,这些钱会流向 AI 代理所代表的机构,但这并不等同于让特定的第三方人员受益。由于 AI 代理本身并不能直接从金钱中获益,因此需要进一步的研究来探讨对 AI 代理的 “回报” 于其他人来说是明确和真正重要的。