




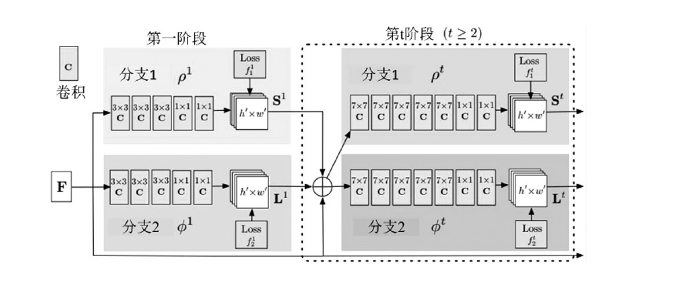
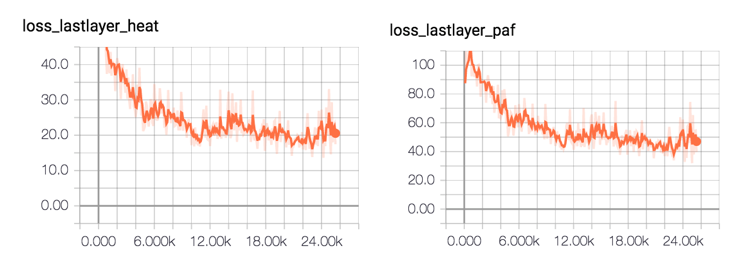
2.2 模型训练通过 TensorFlow 对姿态训练,官方提供了三个模型,分别为:Cmu:基于模型的VGG预训练网络。其中使用TensorFlow将Caffe格式的Weights转换为tensorflow格式。Dsconv:与cmu版本相同的架构,除了移动网络的深度可分离卷积。使用“迁移学习”来训练它,但它提供的速度和准确性都相对较差。Mobilenet:在mobilenet模型的基础上,使用12个卷积层作为特征提取层。为了对小人物进行改进,对体系结构进行了微小的修改。根据网络规模参数学习三种模型。

算法测试
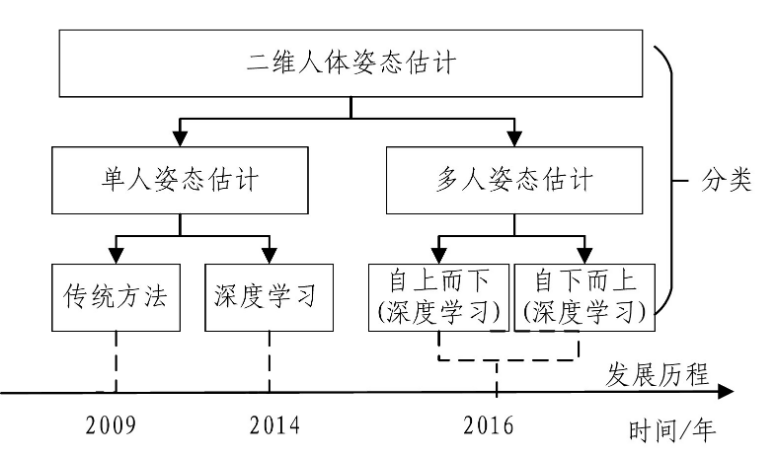
3.1 人体关键点:Openpose算法针对已有"bottom-up"方法缺点:(1)未利用全局上下文先验信息,也即图片中其他人的身体关键点信息;(2)将关键点对应到不同的人物个体,算法复杂度太高。提出了“Part Affinity Fields (PAFs)”方法,即每个像素是2D的向量,用于表征位置和方向信息。基于检测出的关节点和关节联通区域,使用greedy inference算法,可以将这些关节点快速对应到不同人物个体。其中18个关键点对应位置分别如下: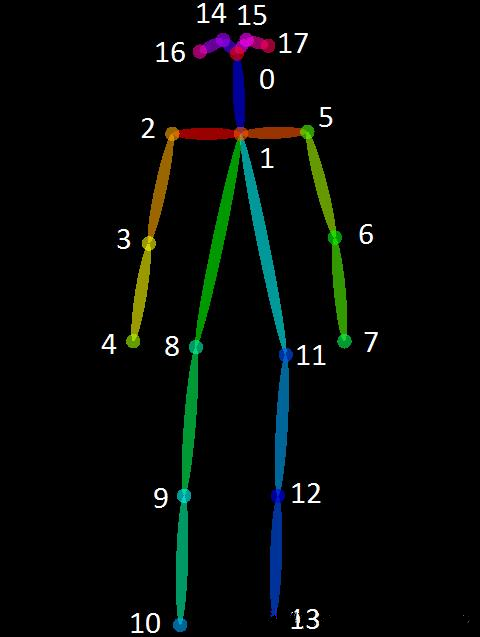
parser =argparse.ArgumentParser(description='tf-pose-estimation run')
parser.add_argument('--image', type=str, default='./images/p2.jpg')
parser.add_argument('--model', type=str, default='cmu',
help='cmu / mobilenet_thin/ mobilenet_v2_large / mobilenet_v2_small')
parser.add_argument('--resize', type=str, default='0x0',
help='if provided, resizeimages before they are processed. '
'default=0x0,Recommends : 432x368 or 656x368 or 1312x736 ')
parser.add_argument('--resize-out-ratio', type=float, default=4.0,
help='if provided, resizeheatmaps before they are post-processed. default=1.0')
args = parser.parse_args()
w, h = model_wh(args.resize)
if w == 0 or h == 0:
e =TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368))
else:
e =TfPoseEstimator(get_graph_path(args.model), target_size=(w, h))
# estimate human posesfrom a single image !
image =common.read_imgfile(args.image, None, None)
image=cv2.resize(image,(600,400))
cv2.imshow("2",image)
if image is None:
logger.error('Image can not beread, path=%s' % args.image)
sys.exit(-1)
t = time.time()
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
elapsed = time.time() - t
logger.info('inference image: %sin %.4f seconds.' % (args.image, elapsed))
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
cv2.imshow("1",image)
cv2.waitKey(0)

来源: AI科技大本营