全部 资讯通知 实用资讯 正文
清华大学教授孙茂松:透过喧嚣,坐看云起,NLP 的迷思与感悟
0
图源:澎湃新闻 2010年深层神经网络在语音识别研究方向上取得里程碑式进展,以这一事件为新起点和新动能,整个人工智能领域迅速跃迁到深度学习时代,包括自然语言处理(NLP)等关键领域也获得了长足发展。 十年间,深度学习在NLP的绝大多数任务上都取得了明显的性能水平提升,近年来更是出现了以BERT和GPT3为代表的大规模预训练语言模型,成为全球人工智能领域技术竞争的战略焦点和热点,甚至引领了一个时期的潮流。 基于深度学习的自然语言处理技术正沿着“极大数据、极大模型、极大算力”的轨道,“无所不用其极”地一路奋进。但这条路走到极致,前景又会是怎样的呢? 放眼看过去,热热闹闹,“乱花渐欲迷人眼”,但在研究上,以及真正解决问题的深刻程度上,似乎却仍停留于“浅草才能没马蹄”的阶段。 清华大学孙茂松教授在“第六届语言与智能高峰论坛”的主旨演讲中,就此类迷思进行探讨。智源社区根据其报告,将核心内容整理如下,供读者参考。 报告人:孙茂松,清华大学教授,智源研究院NLP重大方向首席科学家 整理:张虎,牛梦琳 校对:戴一鸣
总基调:深度学习让NLP提升到了一个新的格局 2010年深层神经网络在语音识别研究方向上取得里程碑式进展,以这一事件为新起点和新动能,深度学习将NLP提升到了一个新的格局。 深度学习将自然语言处理从象牙塔里的理性主义方法中解放了出来,从此可以切实地应用到实际应用中。例如,作为典型的应用场景,机器翻译行业得到了快速的发展。基于深层神经网络的方法比起上一代基于香农信息论的统计机器翻译方法,在翻译效果上有了质的飞跃。 本演讲将从机器翻译出发,来阐释深度学习时代自然语言处理的进展,存在的问题与挑战以及一些解决方法。 一、基于深度学习的机器翻译 基于深度学习技术的机器翻译技术,比上一代基于香农信息论的统计机器翻译方法,在效果上有了显著提升。 目前相当多提供人工翻译服务的企业,一般都会先进行一轮机器翻译,然后再进行人工翻译,这种工作模式会显著提高翻译效率和质量。但是,从翻译专家的角度来看(这里引用美国当代著名学者、认知科学家、曾获普利策非小说奖的《哥德尔、埃舍尔、巴赫:集异璧之大成》作者侯世达先生对谷歌机器翻译效果进行测试后说过的一句话):“机器翻译反映的是企业的目标,而不是哲学的目标”。
由于基于深度学习的机器翻译方法没有对语义信息进行深层次的理解,所以当前的翻译质量只能达到差强人意的程度。100多年前严复先生在《天演论》“译例言”中讲到“译事三难:信、达、雅”三个翻译境界,而现在机器翻译的追求目标还仅停留在“信”这个层次,与“雅”这个层次相差甚远。 下面,针对三大企业提供的机器翻译服务,对当前基于深度学习的机器翻译技术进行案例观察: 首先,随机选取对奥运选手苏炳添的报导中的一段文字,分别在Google翻译,百度翻译,搜狗翻译三个平台上进行中译英的开放测试。尽管三者在模型上有差异,但都能基本正确翻译整段文字,对于长难句中的连词翻译也比较准确,基本做到了“信、达、雅”中的“信”字,这体现了深度学习的威力。对这段文字,搜狗翻译得相对最好,不妨以之体会一下机器翻译目前达到的水平:
但美中不足的是,其中个别较难的问题还是没有处理好。如三个翻译平台都将“唯二”一词错误翻译成了“only”。估计翻译模型在训练语料中没怎么见过“唯二”的译法,所以只好找到了最接近的词语“唯一”,译成“only”。 再试另一个难的例句:“我家门前的小河很难过”,三个平台都把“难过”一词错误地翻译成了“sad”。 最后观察一下世界机器翻译研究先驱Yehoshua Bar-Hillel在其1960年发表的关于机器翻译发展前景判断的著名文章中给出的、貌似非常简单的经典翻译难句:“The box was in the pen”,这三个平台都错误地翻译成“盒子在钢笔里”。在现实世界中,pen其实有两个含义,一是钢笔,二是围栏。要译对这个词,机器需要知道box与pen的大小关系,以及介词in的意思等深层次语义信息。这涉及到无所不包的世界知识。
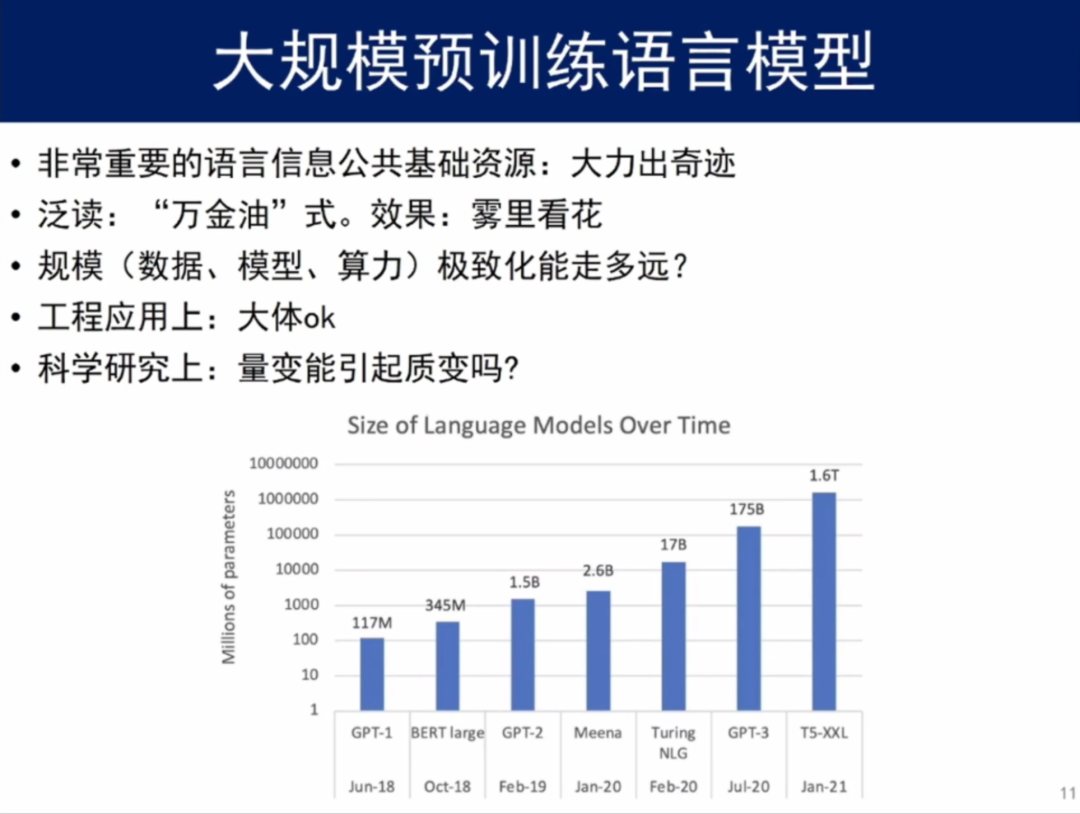
从上面若干案例分析中可以看到:机器翻译需要语义知识乃至世界知识的系统性介入才有可能处理好比较难难的翻译,全自动高质量的机器翻译,目前还做不到。基于深度学习技术的自然语言处理任务,主要还是利用极大规模语料库,目前并没有找到一个较好的方法解决自然语言处理中的深层语义理解问题。 上一代基于理性主义的方法,试图在人工构造语法规则集、语义形式化严重不足的条件下解决翻译问题,这种做法已被实践验证基本行不通;而现有的深层神经网络主要依赖“生”的双语语料库,试图从语料里发现某种对应关系或关联规则,而不去做深度的语义分析——这也是深度学习的最大优势。 然而,正所谓“成也萧何,败也萧何”,利用深度学习的方法来完成机器翻译,从本质上来讲,它并没有真正从深层次语义角度出发来理解这句话。这是它与生俱来的“阿克琉斯之踵”:它不会有意识地利用语义信息,对于未曾遇见的词语,通常会自动选择一个它见过的“形似”词语来猜测,碰到没有见过的更复杂的语义现象,只能撞大运乱猜。 当前机器翻译遇到的“窘境”是可利用的系统性世界知识严重不足,同时缺乏语义分析有效手段。 二、大规模预训练语言模型 从早期的机器翻译,到现在以BERT和GPT-3为代表的大规模预训练语言模型,基于深度学习的自然语言处理技术,已成为了世界范围内整个人工智能领域技术竞争的战略焦点和热点,它也正沿着“极大数据、极大模型、极大算力”的轨道,“无所不用其极”地一路奋进。 毫无疑问,大规模预训练语言模型,是一种非常重要的语言信息公共基础资源。随着深度学习的发展,当前无论学术界还是工业界都需要这样一个公共基础资源。它的最大好处是可以把互联网上所有的语言信息关联起来,使得我们在处理具体任务时,不会基于“一片荒原”,而是基于四面八方已经经过初步耕耘的土地。这个工作无疑是十分重要的,其作用具有普适性和不可或缺性。 同时我们也要注意到,大规模预训练语言模型“包容万象”,实质上是一种“泛读”,类似“万金油”,所以应该会存在“泛而不精”的不足,虽然对每一种语言处理具体任务都有作用,但使用起来的实际效果可能会“雾里看花”,不一定很理想。 尽管不少论文号称通过few-shot便可以实现模型迁移,但相信利用一个专门针对具体任务的一定规模的训练数据集在大规模预训练语言模型上做精调,实际效果应该会更好。 这里面还有若干不太清楚的问题,需要通过研究搞清楚,比如,那些与某个具体任务毫不相干的语料(可以设想这部分语料比相干语料的规模会大很多倍)一股脑地被拿来训练大规模预训练语言模型,是否划算(消耗或占用了太多的各类算力资源)?会不会引入了过多噪音而使针对具体任务的系统性能明显下降呢?
大规模预训练语言模型当前面临着一个最大问题是:规模(指数据、模型、算力)的极致化能走多远?很多著名机构,如百度、北京智源人工智能研究院等,都在努力将规模推到极致,从工程角度来看,极致化是有现实意义的。其实只需有一个这样的模型,如果大家都可以用,就可以了,不必谁都搞一个。 但同时也有不少学者对规模极致化的科学意义提出了质疑。从研究角度来看,极致化到底能走多远是一个问号。人们或许期待量变能引起质变,但是,量变引起质变的前提是需要模型内部存在合理的结构或机制作为支撑。否则好比对牛弹琴,无论弹多久,牛也不能听懂音乐。大规模预训练语言模型很可能会遇到这种瓶颈,量变到相当程度后,其性能增益的趋势将会趋向平缓。 对于目前的大规模预训练语言模型,如GPT-3,虽然已经引入了近乎人类所有的文本,但对语义的控制能力实际上还是很不足的,如这里给出某个典型大规模预训练语言模型生成的一组句子:输入“沿着人满为患的山间小径一路走去,未见”,模型会续以“任何人”。这反映了大规模预训练语言模型的本质缺陷。
语义控制能力不足会导致模型生成的文本显得絮絮叨叨的(尤其是生成长文本),语言逻辑关系似是而非,经不起稍加推敲。 基于GPT-3的文本生成模型依然免不了被人们称为“统计鹦鹉”。
大规模预训练语言模型需要克服的主要挑战与机器翻译“窘境”是完全一样的:可利用的系统性世界知识严重不足,同时缺乏语义分析有效手段。 三、总结 纵观自然语言处理的发展现状中,放眼望去,似乎热热闹闹,各种技术层出不穷,颇有“乱花渐欲迷人眼”之势,但在科学研究的深刻程度上,依旧停留于“浅草才能没马蹄”的境地。深层神经网络在自然语言处理上的“阿克琉斯之踵”——大规模语义和世界知识的建设及运用难题有待破解。 自然语言处理目前或正处于一种“行到水穷处”的阶段。这也是下一代深度学习发展的历史性节点。此时应该保持一种“坐看云起时”的态度,要通过提高研究的理论高度和深刻性来积极摸索破局的办法,以期可以走得更远。