
简介:SARSA(State-Action-Reward-State-Action)是一个学习马尔可夫决策过程策略的算法,通常应用于机器学习和强化学习学习领域中。State-Action-Reward-State-Action这个名称清楚地反应了其学习更新函数依赖的5个值,分别是当前状态S1,当前状态选中的动作A1,获得的奖励Reward,S1状态下执行A1后取得的状态S2及S2状态下将会执行的动作A2。我们取这5个值的首字母串起来可以得出一个词SARSA。
基本原理:它包含了三个参数:(1)学习率 (Alpha)学习率决定了新获取的信息覆盖旧信息的程度。Alpha为0时,表示让代理不学习任何东西,Alpha为1时,表示让代理只考虑最新的信息。(2)折扣系数 (Gamma)折扣因素决定了未来奖励的重要性。Gamma为0时,会让代理变得 "机会主义",只会考虑目前的奖励,而当Gamma接近1时,会让代理争取长期高回报。如果折扣系数达到或超过 1, 则Q的值可能会发散。(3)初始条件 (Q(s0,a0))
由于 SARSA 是一个迭代算法,所以在第一次更新发生之前,它隐式地假定初始条件。一个低 (无限) 初始值,也被称为 "乐观初始条件",可以鼓励探索。无论发生什么行动, 更新规则导致它具有比其他替代方案更高的价值,从而增加他们的选择概率。
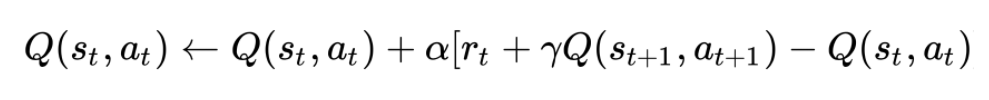
主要应用:强化学习
相关案例: