
简介:Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder。
基本原理:Transformer的本质上是一个Encoder-Decoder的结构,编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入,在Transformer的encoder中,数据首先会经过一个叫做‘self-attention’的模块:
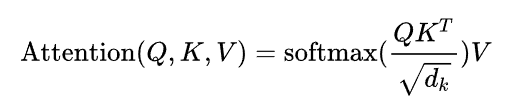
到encoder的下一个模块,即Feed Forward Neural Network。这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,Decoder的结构它和encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值。
主要应用:自然语言处理
相关案例: