

2021 年 10 月 13 日,来自麻省理工学院、加州大学伯克利分校、伊利诺伊大学香槟分校、华盛顿大学、帝国理工学院的六名顶级人工智能科学家、计算机视觉科学家在 ICCV 2021 大会期间进行了题为「A discussion about deep learning vs classical methods and their roles in computer vision」的学术讨论。
参与讨论的嘉宾包括 Aude Oliva(MIT-IBM Watson 人工智能实验室)、Svetlana Lazebnik(伊利诺伊大学香槟分校)、Jitendra Malik(加州大学伯克利分校)、Andrew Davison(帝国理工大学)、Richard Szeliski(华盛顿大学)、Alexei Efros(加州大学伯克利分校)。
1 深度学习 vs 传统方法

Richard Szeliski 首先抛砖引玉,发表了题为「Deep vs Classical Methods」的简短演讲。Richard 提到,在设置人工智能专业课程时,一个广为讨论的话题是:我们是否应该讲授深度学习之前的传统方法?还是直接通过深度学习解决所有的问题?
为此,Richard 在过去的四年中持续更新他的计算机视觉教科书(https://szeliski.org/Book)。相较于早先的版本,该书加入了信号处理、优化技术等章节,这些知识经常被用于计算机视觉的各个领域。在「Deep Learning」和「Recognition」两个章节中,Richard 分别介绍了深度学习的基本原理(传统的网络架构),以及一些更加复杂的技术(例如,分割、目标检测、视觉和语言)。
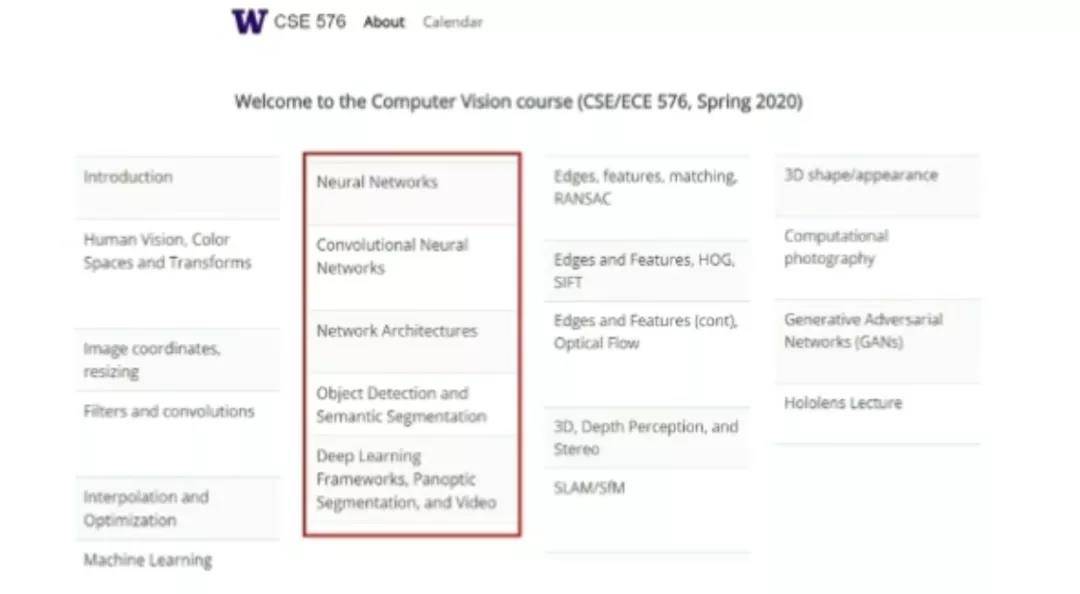
实际上,在华盛顿大学「计算机视觉」的课程安排中,老师们会首先介绍经典的信号处理算法,接着介绍神经网络和深度学习。在此基础上,老师们会进而讲解一些经典的技术和应用(例如,3D 计算摄影、神经渲染等)。

密歇根大学的计算机视觉课程 EECS 442 将期中的很大一部分内容设置为深度学习相关的内容,但在此之前也会介绍经典的信号处理、特征提取技术。最后,教师会讲解 3D 视觉和经典计算机视觉的内容。此外,这门课的任课教师 Justin Johnson 还专门针对神经网络开设了一门课程,更为详细地介绍了循环神经网络、Transformer 等内容。

尽管深度学习已经成为了计算机视觉领域的主流方法,但是仅仅依靠深度学习技术是否能解决所有的计算机视觉问题呢?在论文「What Do Single-view 3D Reconstruction Networks Learn?」中,在基于 ShapeNet 进行 3D 重建时,网络只是在识别对象的类别,然后细化形状,并没有很好地利用图像的底层信息。

以视觉定位任务为例,一些基于深度学习的方法只是记住了图片出现的场景,在定位时进行猜测。如果查询并没有沿着路径,则回归的结果可能始终会被引导到出发点。该过程中并没有任何的 3D 推理,没有利用 3D 几何结构。

另一方面,利用语义信息完成 3D 重建等任务也是一条很好的思路。论文「Joint 3D Scene Reconstruction and Class Segmentation」发表于 2013 年,那时是深度学习兴起的早期阶段。通过识别建筑和树的部位,该方法可以更好地进行 3D 重建,这说明有时引入语义信息是十分有效的。

在单目深度估计任务中,我们往往在 KITTI 数据集或一些驾驶场景中进行训练和测试。大多数的神经网络模型只是识别物体在图像中的位置,然后为其赋予一个相应的深度。如果我们将一个网络没见过的物体(例如,冰箱或狗)放在路的中间,神经网络可能会完全忽略掉该物体。在驾驶场景下使用这种神经网络模型的安全性值得商榷。

当我们可以用一个很大的数据集训练时,神经网络往往可以表现出很好的性能。然而,如果我们在某个数据集上训练网络,该网络在不被重新训练的情况下会在另外的数据集上表现出怎样的性能?
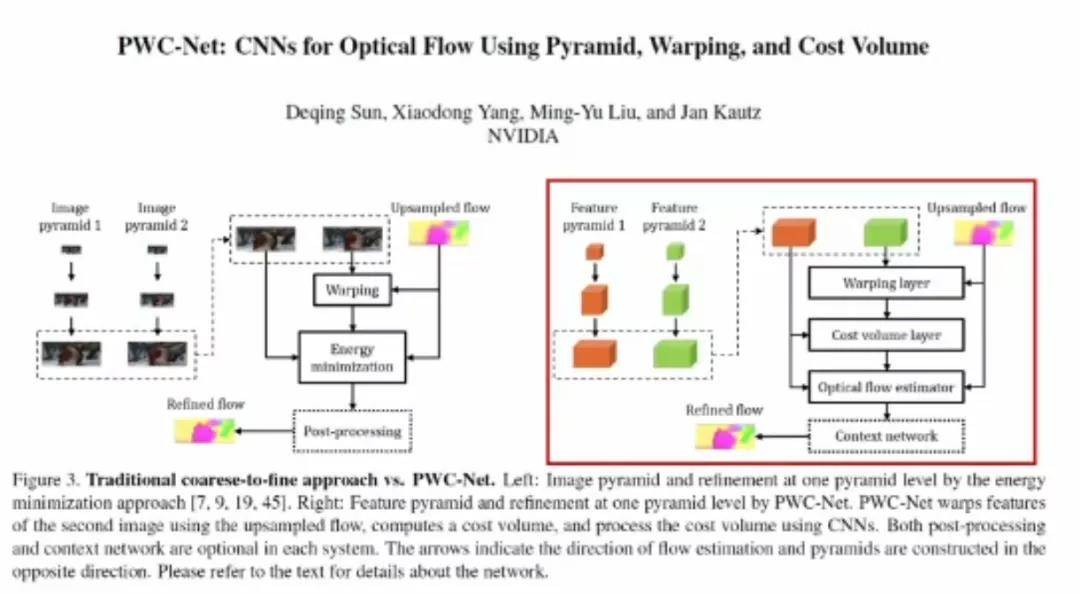
经典方法(例如,光流法)和用于提取特征的神经网络技术可以很好地结合起来。因此,许多深度学习技术使传统方法获得了新生。论文「PWC-Net」的作者使用前馈神经网络代替了经典的能量最小化方法,该模型运行速度更快,也更可靠。此外,在论文「Fast Image Processing with Fully-Convolutional Networks」中,作者使用全卷积网络代替一系列经典的计算摄影技术,加速了其运算过程。

在论文「Animating Picture with Eulerian Motion Fields」中,Richard 等人通过提取神经网络特征,接着将这些特征解码为彩色像素来合成图像。

在 Richard 看来,从事 CV 研究的学生和工程师不仅仅要会使用深度学习方法,也要学习其它类型的 CV 技术。如果我们可以从数学上对几何、光学、物理等性质建模,就要大胆地使用这些方法,它们的性能和泛化能力更强。尤其是当我们拥有的数据十分有限时,使用基于学习的方法就要特别小心。有时,神经网络及其特征提取过程相较于传统方法更快。

Richard Szeliski 是华盛顿大学的兼职教授、美国国家工程院院士、ACM Fellow和 IEEE Fellow。Szeliski 在计算机视觉、基于图像的建模、基于图像的渲染和计算摄影的贝叶斯方法领域进行了开创性的研究,这些领域处于计算机视觉和计算机图形的交叉点。
Szeliski 1988 年获得卡内基梅隆大学计算机科学博士学位。他于 2015 年加入 Facebook,担任计算摄影小组的创始董事,并于 2020 年退休。在加入 Facebook 之前,他在微软研究院以及其他几个工业研究实验室工作了二十年 。
他在计算机视觉、计算机图形学、神经网络和数值分析方面发表了 180 多篇研究论文,并撰写了《计算机视觉:算法与应用》和《低级视觉不确定性的贝叶斯建模》。他是 CVPR'2013 和 ICCV'2003 的程序主席,曾担任 IEEE Transactions on Pattern Analysis and Machine Intelligence 和 International Journal of Computer Vision 编委的副主编,以及Foundations and Trends in Computer Graphics and Vision的创始编辑。
2 在马尔CV三层次之前,先回答廷伯根四问

计算机视觉是「数学」、「科学」、「工程」的结合。许多论文将这些元素融合在了一起。
David Marr 最重要的观点是将视觉作为一种科学来思考。上世纪 70 年代末期,他指出我们应该从三个层次理解计算机视觉任务:(1)计算理论:底层的物理约束(2)算法(3)硬件上的算法实现。实际上,早在上世纪 50、60 年代,1973 年的诺贝尔生理和医学奖得主、生物学家廷伯根就做了一系列工作,有助于我们在如今思考基于学习的计算机视觉和传统方法之间的关系。
简而言之,廷伯根最为著名的贡献是围绕动物展现出特定行为的方式和原因提出了四个基本问题:(1)行为的动因和机理(2)行为随年龄、经验、环境的发展(3)进化对行为的影响(4)行为对生存的作用。
试想一下,人类视觉系统如何感受到「深度」?
从机理层面上来说,神经网络中存在视网膜、感光神经元等组件,它们会产生多层计算。我们看到的两幅(双目)图的差别让我们可以感受到「深度」。
从行为发展(发育)的角度来说,婴儿初生之时,其感官系统并不能很好地工作,随着时间的迁移,孩子会学会一些技能,学会观察物体的运动。那么,在现实世界中,我们应该如何训练这样的神经网络?
以上两个问题与行为的方式(How)有关,但是我们还需要回答关于「Why」的问题,探究人类为什么会发展出这样的行为。从生物进化的角度来说,发展出双目系统的捕食者可以捕获只有一侧有眼睛的猎物。从功能的角度来说,这些行为对物种的生存是有益的。
从计算机视觉的角度来看,我们需要思考如何构建某种神经架构来捕获这些信息,还需要考虑究竟是使用监督学习、无监督学习,还是自监督学习来完成该任务。上述这些问题是互补的。

在 Jitendra 看来,我们可以通过训练一个大型的神经网络来获得工程应用所需要的能力。但是其背后的原理需要通过光学和自然世界中的统计结果来解释。这有助于我们应对计算机视觉领域发生的巨大变化。如今,我们正处于从监督学习范式转向自监督学习、弱监督学习等范式的过程中。
此外,我们正处于大数据的「陷阱」中。未来,监督信号将从「人工」走向「自然」,我们使用的「大数据」在更多情况下将转变为「小数据」。因此,少样本学习是十分重要的,而这就要求我们设计更多新的网络架构。
温故而知新,了解智能学科的发展历史有助于我们成为更好的研究者!

Jitendra Malik 1986 年 1 月加入加州大学伯克利分校,他目前是电气工程和计算机科学系的 Arthur J. Chick 教授。他还是生物工程系、认知科学和视觉科学组的教员。2002-2004年任计算机科学系主任,2004-2006年和2016-2017年任EECS系主任。2018 年和 2019 年,他在 Menlo Park 担任 Facebook AI Research 的研究总监和站点负责人。
Malik 教授的研究小组致力于计算机视觉、人类视觉计算建模、计算机图形学和生物图像分析等许多不同的主题。
他于 1980 年获得 IIT Kanpur 电气工程最佳毕业生金奖,并于 1989 年获得总统青年研究员奖。他的论文获得了无数最佳论文奖,其中包括五项时间检验奖 - 因在 CVPR 发表的论文而获得的 Longuet-Higgins 奖(两次)和在ICCV发表的论文而获得的 Helmholtz 奖(3次)。他获得了 2013 年 IEEE PAMI-TC 计算机视觉杰出研究员奖,2014 年 K.S.国际模式识别协会傅奖、2016年ACM-AAAI艾伦纽厄尔奖、2018年IJCAI人工智能卓越研究奖、2019年IEEE计算机学会计算机先锋奖。他是 IEEE Fellow和 ACM Fellow 。他是美国国家工程院院士和美国国家科学院院士,美国艺术与科学院院士。
3 讨论环节
Q1:这十年来,从经典方法到深度学习方法的转变是如何发生的?请问 Svetlana,在你的研究过程中,这一过程是自顶向下的,还是自底向上的?也就是说,导师们发现了深度学习的强大,并将其介绍给了学生们;还是学生们将这一技术推荐给了导师?
Svetlana:我的经历也许与许多研究者相似。我记得「Alexnet」是深度学习时代到来的重要里程碑,它在 ImageNet 竞赛中一举夺冠,并在 ECCV 2012 上发表了研究论文。Alexei 当时还和 Yann LeCun 等人就此事进行了争论,Alexei 对神经网络持怀疑态度,他认为用这些网络进行分类任务并不具有说服力,使用神经网络完成检测任务才可以说服他。就我个人而言,一开始我也怀疑自己是否能够参与这类研究,因为这些方法就好像魔法,其中有太多的奥秘。我不知道这些结果是否可以复现,是否会被研究社区所接受。
令人高兴的是,这些年过去了,我的怀疑被证明是错误的。人们发明了 Caffe 等好用的程序包,2013、2014 年前后,学生们开始研究此类方法,那时你甚至只需为自己的特定数据集训练一个 Alexnet 或者使用现成的特征就可以发表研究论文。而如今,研究走进了深水区,竞争越来越激烈,我又变得悲观了起来。

Svetlana Lazebnik 在2006 年获得伊利诺伊大学计算机科学博士学位。2007 年至 2011 年在北卡罗来纳大学教堂山分校担任助理教授后,她返回伊利诺伊大学任教,目前担任计算机科学系正教授。她获得的奖项包括 NSF CAREER 奖(2008 年)、微软研究院研究奖(2009 年)、斯隆研究奖(2013 年),并当选 IEEE Fellow(2021 年)。她于2006年发表在 CVPR 的关于空间金字塔匹配的论文获得了 2016 年 Longuet-Higgins 奖,该论文对计算机视觉有重大影响。她曾担任 ECCV 2012 和 ICCV 2019 的程序主席,目前担任国际计算机视觉杂志的主编。她的主要研究主题包括场景理解、大规模照片集的建模、图像和文本的联合表示以及视觉识别问题的深度学习技术。
Q2:Lana 提到了当年 Alexei 和 Yann 争论的轶事,请问 Alexei 现在回过头怎么看待当时的争论?
Alexei:
2011 年前后,我曾去纽约大学呆了几个月,在 Yann LeCun 那里试图理解神经网络。那时,我认为人们还没有准备好步入深度学习时代,神经网络在 ImageNet 上的效果并不能说服我,我认为分类任务比检测任务简单得多。然而,大概一年之后,RCNN 横空出世,他们证明了深度学习在检测任务上也是可行的。
我是一个非常保守的研究者,不会轻易投身于所谓的研究潮流(例如,图模型、VAE 等)中。尽管我和 Jitendra 等人做了很多与深度学习的诞生相关的关键工作,但是我那时没有立刻开展深度学习研究。我一直在等待深度学习成为一种工具,我所擅长的是解决视觉问题,而非研究网络架构。
后来,我和同事们听说神经网络受益于 ImageNet 预训练,在 Pascal 数据集上有很好的效果。然而,Pascal 数据集中的数据分布与 ImageNet 是截然不同的。因此,我猜想预训练所带来的性能提升可能并不是由于 ImageNet 的标签,而是由于像素中的信息。
那时,我对 Jitendra 说 1 年之内会出现一些无需 ImageNet 的标签来预训练 RCNN 的工作,这实际上也是自监督学习的动机之一。在 ICCV 2015 上,大量有关自监督学习的文章涌现了出来。如今,自监督学习成为了重要的预训练方式。

Alyosha Efros(Alexei Efros)是加州大学伯克利分校的教授。他于 2003 年从加州大学伯克利分校获得博士学位,并在牛津、CMU 和 INRIA/Paris 度过了一段时间,然后于 2013 年回到伯克利。Alyosha 是数据、像素、最近邻和简单有效的事物的忠实粉丝,而对复杂(尤其是概率)模型、语义标签和语言持怀疑态度。
Q3:Andrew Davison 是 SLAM 领域的专家。请问深度学习对你们研究小组的工作有何影响?
Andrew:
我很早就听说过深度学习相关的研究,但那时这与我的研究兴趣相去甚远。直到 2016 年,我才在论文中加入了深度学习的相关技术,用它来解决一些之前难以解决的问题,向 3D 地图加入一些语义信息。在深度学习出现之前,我们可能会通过随机森林等方法来完成该任务。在当时,深度学习这类新的技术取得了巨大成功,人们开始常识使用该技术进行深度估计等任务。相较于传统方法,深度学习技术有时更快也更准确。
因此,我们开始研究如何在 SLAM 领域使用深度学习技术代替手动设计的先验,在这个方向发表了一系列文章。具体而言,我们通过深度学习进行深度预测和多视图优化等工作。然而,大约 2018 年之后,人们发现深度学习技术存在一些系统性误差,网络预测出的深度和方向可能是错误的,我们需要通过多视图的方式来解决这些问题。在我看来,通过深度学习提取的像素级特征向量比手动设计的特征要更加强大,但有时我们也需要回到更传统的几何学、概率化的多视图优化研究上来。

Andrew Davison 是伦敦帝国理工学院机器人视觉教授兼戴森机器人实验室主任。他的长期研究重点是 SLAM(同步定位和映射)及其向通用“空间 AI”的演变:计算机视觉算法,使机器人和其他人工设备能够映射、定位并最终理解周围的 3D 空间并与之交互。他与他的研究小组和合作者一直在开发具有突破性意义的系统,包括 MonoSLAM、KinectFusion、SLAM++ 和 CodeSLAM,最近的奖项包括 ECCV 2016 最佳论文和 CVPR 2018 最佳论文荣誉提名奖。他还积极参与将这项技术转化为实际应用,特别是通过他与戴森合作设计了戴森 360 Eye 机器人吸尘器内部的视觉映射系统。他当选了2017年英国皇家工程院院士。
Q4:Oliva 是人类感知和认知神经科学领域的专家,就你们的领域而言,深度学习对你们的研究带来了哪些变化?有何前景?
Oliva:在认知神经科学领域,我们对此持乐观态度,积极拥抱这种改变。事实上,早在 2011 年我很幸运地将实验室的研究领域从神经科学拓展到了计算机科学。那时,我们开始讨论 Alexnet。
从神经科学家的角度出发,我们认为神经网络是复杂的黑盒。我们开发了一系列方法来研究大脑黑盒的功能。当我们看到一些关于人工神经网络的论文时,一些神经科学家认为人工意义上的大脑为我们带来了一个新的研究领域。他们使用神经科学的方法来研究深度学习模型。
我的研究小组试图为对深度学习模型中的每一层进行评估,提供一些可解释性,并在神经科学的启发下设计一些深度学习模型。此外,我有一些从事计算神经科学的同事开始比较各种物种和人造神经网络,我认为深度学习极大促进了计算神经科学的发展。

Aude Oliva博士 是 MIT-IBM Watson AI Lab 的 MIT 主任,也是 MIT Quest Corporate 和 MIT Schwarzman 计算学院的主任,领导与行业的合作,将自然和人工智能研究转化为更广阔世界的工具。她还是计算机科学和人工智能实验室的高级研究科学家,她负责领导计算感知和认知小组。她的研究是跨学科的,涵盖人类感知和认知、计算机视觉和认知神经科学,并专注于所有三个领域交叉的研究问题。
Q5:在机器机器学习、计算机视觉、自然语言处理等任务中,有一些不易察觉的研究领域正在悄然萌芽。「几何深度学习」就是其中一个研究方向,相较于传统的 CNN,几何深度学习引入了一些其它类型拓扑的归纳偏置,为编码先验知识提供了新的方式。几何深度学习有助于传统方法在深度学习时代焕发新生。另一方面,「具身人工智能」(行为主义人工智能)也是具有广阔前景的研究方向。请问在深度学习领域中,未来有哪些具有潜力的研究方向?
Jitendra:
我曾经与同事们针对图神经网络开展过一些研究。我认为,这一领域的研究将会与如今的 Transformer 结合起来,这是因为 Transformer 可以更将灵活地通过位置编码等方式构建各种约束。我认为,人们对此类架构的研究正在进行中,我们还没有看到其最终的形态。CNN 和 Transformer 在近年来掀起了两波研究浪潮,今后还会有更多新的思路会引入其它的归纳偏置。在我看来,引入合适的归纳偏置对于解决少样本学习问题十分重要。
就我个人而言,我对具身人工智能的研究充满热情,我认为深度学习与其是相辅相成的。如前文所述,计算机视觉领域的问题可以被划分为多个层次,我们不应混淆它们。深度学习的强大之处在于,我们可以将一些可微的参数化的功能模块连接起来,使用 SGD 等方法进行梯度下降训练。神奇之处在于,这些过参数化的模型确实奏效,它们往往不会被困在局部最小值,可以在许多任务上取得成功。深度学习的成功与你是否使用监督学习、自监督学习、强化学习无关。
我认为,具身人工智能是人工智能的另一个层次,它将视觉和动作结合了起来。典型的应用场景包括机器人、AR 等,人们需要投入更多的资金和数据,来实现这个 1950 年代就产生的梦想。
Q6:以前,计算机视觉工程师们需要花费大量时间设计针对特定领域、特定物体的算子、时空度量。但现在,「特征工程」在有些研究者眼中或许已经稍显落伍了。现在流行的对比学习等方法用到了一些特征增强手段。或许,未来特征增强也会落伍,如何看待这种变化?
Svetlana:
我对此持开放态度。从长远的角度来看,研究社区需要保持繁忙。15 年前,大家都在设计手工的算子,现在大家都在做手工的神经网络设计、数据增强,也许在下一个 5 到 10 年,大家都会投身到手工设计元学习技术。我认为这都是可以接受的,重点在于要保持大的研究愿景。
实际上,和计算机视觉一样,神经网络也有着悠久的历史,Alexnet 等模型的诞生也有其历史渊源。神经网络只是我们可以利用的工具之一,我们要做的是维持合适的概念框架,让各种工具发挥作用。
Alexei:
除了 ICCV 之外,计算机视觉领域还有一个顶级会议叫做 CVPR(computer vision and pattern recognition)。我认为这个名字起的非常好,因为我们的研究一方面涉及计算机视觉、另一方面也涉及模式识别。在我看来,这两个部分分别对应是否需要使用数据。
我曾经去牛津大学做过博士后研究,VGG 组确实是做几何计算机视觉的好地方,但是计算机视觉和模式识别并不应该严格地被二分开来。我们需要意识到的是,数据是非常重要的,但数据也并不是全部,我们要将 CV 和 PR 结合起来。
Q7:相对而言,深度学习对 SLAM 研究社区的影响似乎还没有那么大。实际上,目标跟踪和各种滤波器也可以被用于 SLAM 领域。如何看待 SLAM 领域中各种工具的变化呢?
Andrew:
我认为这些工具仍然在发展中。但是显然,深度学习在 SLAM 领域中并没有完胜传统方法。我个人喜欢从整体应用的角度来思考 SLAM 问题,它是具身 AI 或实时感知、三维场景理解的一部分。在拥有足够的数据、网络规模足够大的情况下,人们也许会通过端到端的学习识别地图,建立模型。具体的实现细节(基于学习技术或人工设计)都只是一些计算的模式,相较于此,我更加关注整体过程的可行性。我更加关注如何将这些技术融入到整体的计算框架中,解决有趣的问题。
Richard:
正如 Lana 所说,神经网络的历史可以追溯到上世纪 50 年代。但是神经网络技术直到 2012 年才在大量真实任务上具备可观的性能。传统的计算机视觉课程中并没有深度学习的部分,那时我们会教学生如何设计线性、非线性滤波器。而深度学习方法可以通过多层网络学习出滤波器的权重。
我们可以从分析和经验两个方面来看待视觉识别任务。「经验」指的是神经网络可以记住数据,构建一个在数据中完成内插的系统。然而,这种系统并不一定具有很好的外推能力。如果你可以通过经典的数学、集合、光学方法建模,我认为你需要积极尝试这些方法,而不应该假设神经网络可以解决任何问题。
Jitendra:
我们不妨考虑一下经济学领域。人类是经济学中复杂的实体。我们往往会通过机器学习等基于数据的技术来解决经济学中的预测问题。但是当我们想要理解预测结果时,我们会使用一些简化的模型进行分析。
我认为,对于未来的深度学习研究而言,对模型的理解是十分必要的。机器学习理论似乎并不能胜任这项工作(例如,双下降现象)。神经网络似乎在学习过程中会记住数据,形成经验。现在许多论文所做的工作是针对以往的工作进行数据增强、调整训练参数,而取得的 1-2 个百分比的性能提升可能是由于完全无关的因素,而不是由于论文所提出的核心思想。
如今深度学习模型正变得越来越大,这样一来,只有谷歌、Facebook、亚马逊、微软这样的单位可以从事下一代研究,这对研究社区来说并不是一个好的现象。我希望研究社区可以出现一些创新的思路,我们或许可以从历史中寻找一些灵感。
Q8:现在的深度学习模型参数量越来越大(例如,GPT-3),训练成本越来越高,我们是否有必要回过头研究那些曾经看似复杂的传统方法?如何看待记忆引擎?
Oliva:
十年前,我们进行了大量的记忆实验,让人们在数小时内看上千张图片,然后测试他们的记忆。令人惊讶的是,他们可以记住 90% 的图像。我们可以构建一种复杂的系统来研究人类的大脑,构建起认知科学到计算机科学的桥梁,通过实验的方法来研究这些模型。
来源: 图灵人工智能