4.3 实践学习体验:训练机器执行一个动作 
卷积神经网络(CNN)主要应用于计算机视觉领域,并在各种测试案例上成功达到了最先进的性能。CNN中的隐藏层一般是卷积层和池化层(如果不懂的话,可以看做一层就是一个程序模块)。在每个卷积层中,我们取一个小尺寸的滤波器(也称为卷积核,是一个小尺寸的权重矩阵),并将该滤波器在图像上移动,进行卷积数学运算,来达到减少样本数的效果。卷积运算做法就是在过滤器中的数值和图像中的像素之间进行逐元素矩阵乘法,并将结果值相加。
| CNN: 卷积神经网络 |
|---|
| 卷积神经网络(CNN)是一种前馈神经网络,一般通过处理网格状拓扑结构的数据来分析视觉图像。它也被称为ConvNet。卷积神经网络一般用于检测和分类图像中的物体。 |
CNN在计算上也很有效率。它使用特殊的卷积和池化操作,来实现参数共享。这使得CNN模型可以在任何设备上运行,从而得到普遍青睐。这一切听起来都像是纯粹的魔法:作为一个非常强大和高效的模型,它进行自动特征提取,以达到非一般的精度。所有的CNN模型都遵循类似的架构,如图25所示。
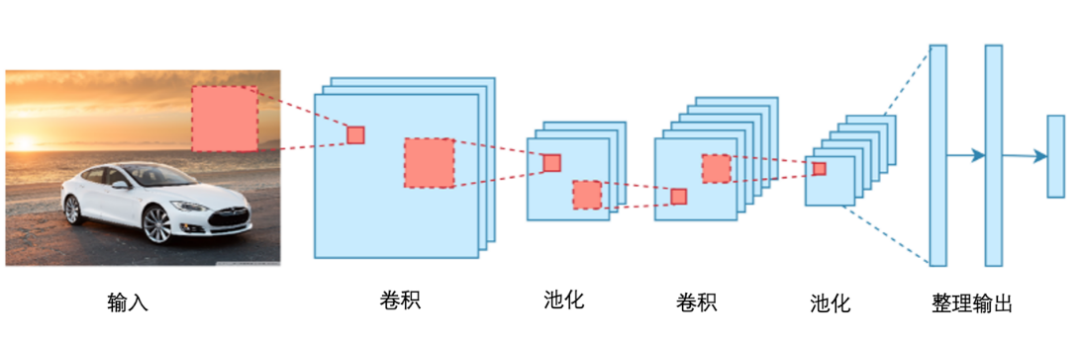
现在,让我们继续学习池化层。池化层是用来缩小图像大小的。图像会包含大量的像素值,如果逐步缩小图像的大小,通常可以使网络很容易学习到特征。池化层有助于减少所需参数的数量,因此,这减少了所需的计算量。有两种类型的池化操作可以完成。
- 最大池化——选择最大值
- 平均池化——将所有数值相加,然后除以数值总数
在我们开始编码之前,你需要知道我们要使用的数据集是MNIST数字数据集(手写数字专用数据集),我们将使用Keras库和Tensorflow框架来建立模型。好了,准备充分之后,让我们来编写代码。
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2Dimport numpy as np
首先,让我们做一些必要的导入。keras库帮助我们构建卷积神经网络。我们通过 keras 下载 mnist 数据集。然后,我们导入一个序列模型,这是一个预建的keras模型,你可以在其中添加层。接着,我们引入卷积层和池化层。我们还导入了全连接层,因为它们是用来预测标签的。dropout层可以减少过拟合,扁平化层可以将三维向量扩展为一维向量。最后,我们导入numpy进行矩阵操作。
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
上面代码中的大部分语句都会很琐碎,这里只对一些代码行进行解释。首先我们重构x_train和x_test,因为我们的CNN只接受一个四个维度向量。值60000代表训练数据中的图像数量,28代表图像大小(即长和宽都是28),1代表通道数。如果图像是灰度的,通道数设置为1,如果图像是RGB格式的,通道数设置为3。我们还将目标值转换为二进制类矩阵。要想知道二进制类矩阵是什么样的,请看下面的例子。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28,28,1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
我们建立一个序列模型,并在其中添加卷积层和最大池化层。我们还在中间添加了dropout层,dropout会随机关闭网络中的一些传递数值,从而迫使数据兼顾新的神经传导路径。我们在最后添加了全连接层来整理数值,最终输出的结果是用来进行类别预测,也就是猜测手写的数值是否为0到9的数字。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
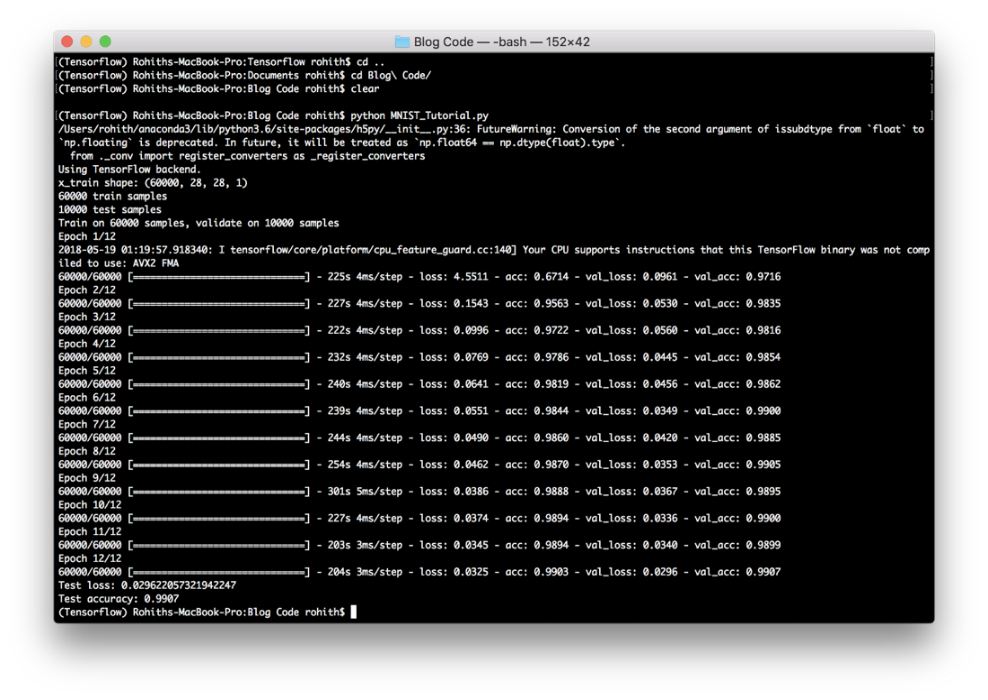
然后,我们将数据集拟合到模型上,即我们对模型进行12次迭代(回合)的训练。训练完模型后,我们评估模型在测试数据上的函数损失和准确性,并打印出来(见图26).也就是判断每次输入的手写数字,最后猜测是否为正确分类结果。
测试
请在我们的jupyter服务器上测试代码并进行练习,默认账户名yuanzhuo,默认密码yuanzhuo. 请将kernel设置为conda-yuanzhuo-tf-chapter4. (https://code.yuanzhuo.bnu.edu.cn/)
测验
深度学习是如何工作的?
关于卷积神经网络(CNN),哪项说法不正确?