5.3 实践学习体验: 句子切分 
自然语言处理技术涉及如何处理句子标记和制定文档向量。句子切分(也叫句子划分)是将一段书面语言划分为句子。看起来似乎非常简单,例如在英语以及其他的一些语言中,只要看到了标点符号,就将句子分割开。但是也会存在一些问题,如英文中的缩略语可能会存在句号,在处理过程中这是需要考量的因素。在处理原始文本时,需要一个包含句号的缩写字典,它可以帮助我们在句子分割中避免句子边界的切割错误。在很多情况下,我们使用语料库来完成这项工作。
举个例子,我们来看一段关于著名的棋牌游戏西洋双陆棋的文字 “Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two-player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.”
text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two-player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice."
sentences = nltk.sent_tokenize(text)
for sentence in sentences:
print(sentence)
print()
作为输出,我们分别得到三个组成部分的句子
Backgammon is one of the oldest known board games.
Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East.
It is a two-player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
基于此,我们可以学习如何处理词袋模型(bag-of-word)和统计文档向量。词袋模型(bag-of-word)是我们在处理文本时使用的一种流行而简单的特征提取技术。它描述了文档中每个词的出现情况。 要使用这个模型,我们需要:
设计一个已知词的词表(也叫标记)
选择已知词语存在的属性
在词袋模型中,任何关于词的顺序或结构的信息都会被抛弃,只考量词语在词表中的属性。这个模型可以了解一个已知的词是否出现在文档中,但不知道这个词在文档中的位置。一般来讲,相似的文档有相似的内容。同时,也可以通过内容了解到文档的含义,需要两个步骤
1. 加载数据
我们有一个review.txt文件,它是我们的数据,要把它作为一个数组来加载。文件内容是:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
为了实现这一点,我们可以简单地读取文件,并按行分割
with open("simple movie reviews.txt", "r") as file:
documents = file.read().splitlines()
print(documents)
输出是
'I like this movie, it's funny.', 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.'
2. 设计词表
让我们从四个句子中获取所有独特的单词,忽略大小写、标点符号和单字标记。这些词将成为我们的词表(已知词)。因此,我们需要对每个文档中的单词进行评分。这里的任务是将每个原始文本转换为数字的向量。最简单的打分方法是若该单词存在,则用1标记,若单词不存在,则用0标记。
现在,让我们看看如何使用上面提到的CountVectorizer类创建一个词袋模型。
# Import the libraries we need
from sklearn.feature_extraction.text
import CountVectorizerimport pandas as pd
# Step 2. Design the Vocabulary
# The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output
count_vectorizer = CountVectorizer()
# Step 3. Create the Bag-of-Words Model
bag_of_words = count_vectorizer.fit_transform(documents)
# Show the Bag-of-Words Model as a pandas DataFrame
feature_names = count_vectorizer.get_feature_names()
pd.DataFrame(bag_of_words.toarray(), columns = feature_names)
输出如下所示
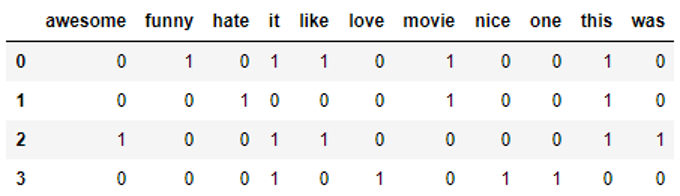
对照一下我们的文本内容,这种学习方式就是NLP中自然语言的基本处理方式
I like this movie, it's funny.I hate this movie.This was awesome! I like it.Nice one. I love it.
测试
请在我们的jupyter服务器上测试代码并进行练习,默认账户名yuanzhuo,默认密码yuanzhuo. 请将kernel设置为conda-yuanzhuo. (https://code.yuanzhuo.bnu.edu.cn/)
小测
请选择适当的利用自然语言处理(NLP)对抗新冠肺炎的例子
自然语言过程(NLP)的主要内容是什么?