
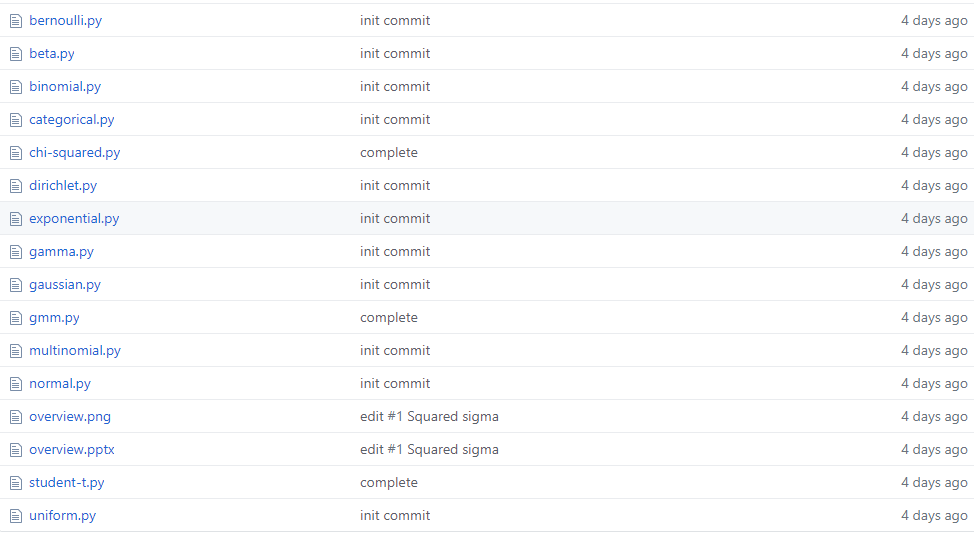
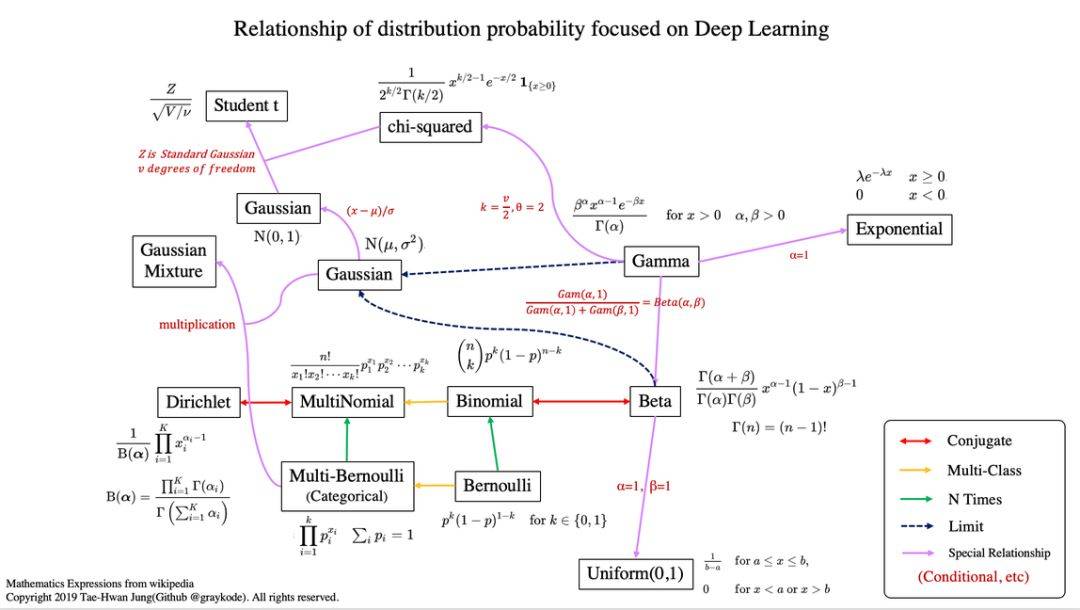
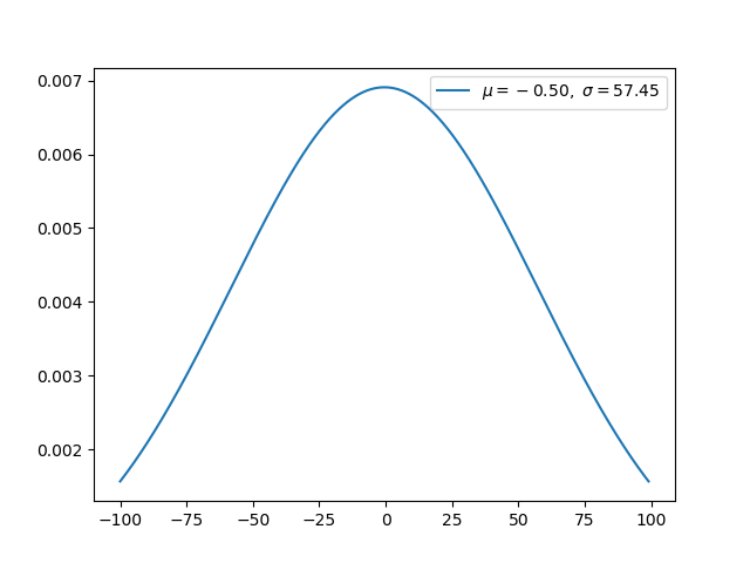
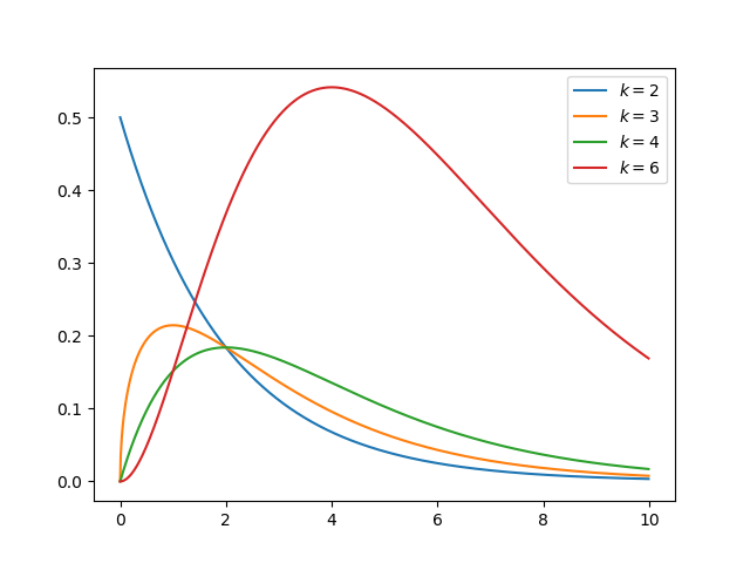
机器学习有其独特的数学基础,我们用微积分来处理变化无限小的函数,并计算它们的变化;我们使用线性代数来处理计算过程;我们还用概率论与统计学建模不确定性。在这其中,概率论有其独特的地位,模型的预测结果、学习过程、学习目标都可以通过概率的角度来理解。 与此同时,从更细的角度来说,随机变量的概率分布也是我们必须理解的内容。在这篇文章中,项目作者介绍了所有你需要了解的统计分布,他还提供了每一种分布的实现代码。 项目地址:https://github.com/graykode/distribution-is-all-you-need
from matplotlib import pyplot as plt
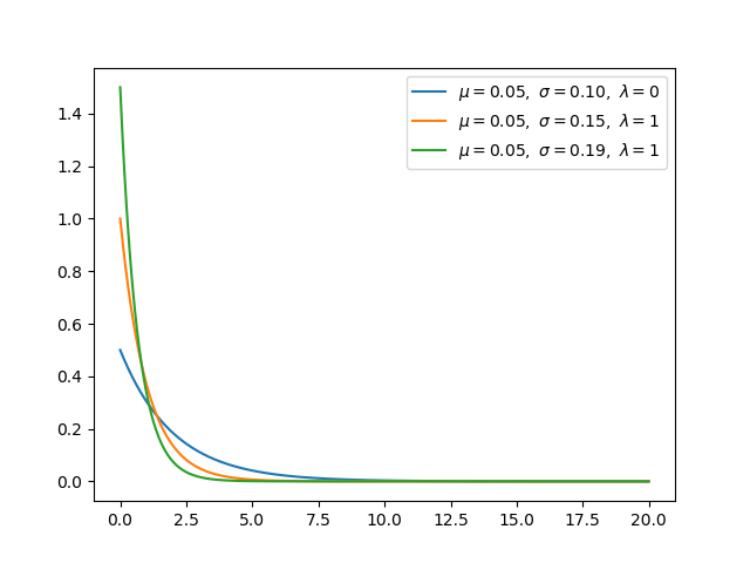
def exponential(x, lamb):
y = lamb * np.exp(-lamb * x)
return x, y, np.mean(y), np.std(y)
for lamb in [0.5, 1, 1.5]:
x = np.arange(0, 20, 0.01, dtype=np.float)
x, y, u, s = exponential(x, lamb=lamb)
plt.plot(x, y, label=r'$mu=%.2f, sigma=%.2f,'
r' lambda=%d$' % (u, s, lamb))
plt.legend()
plt.savefig('graph/exponential.png')
plt.show()
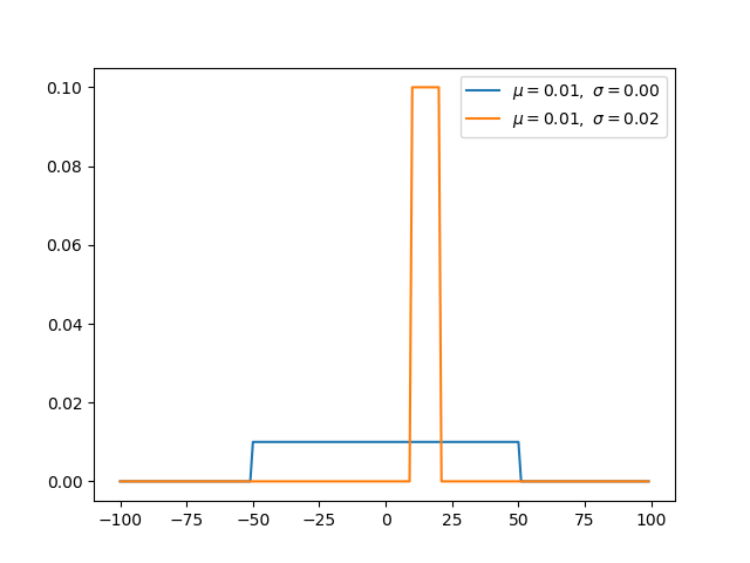
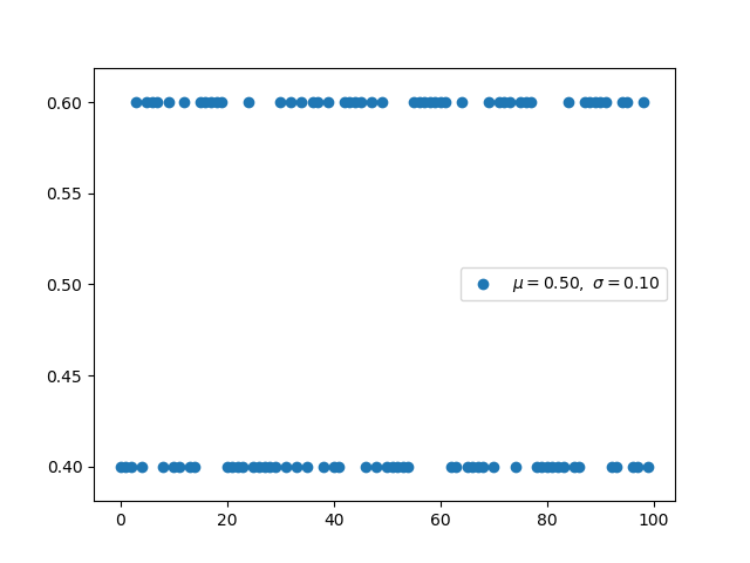
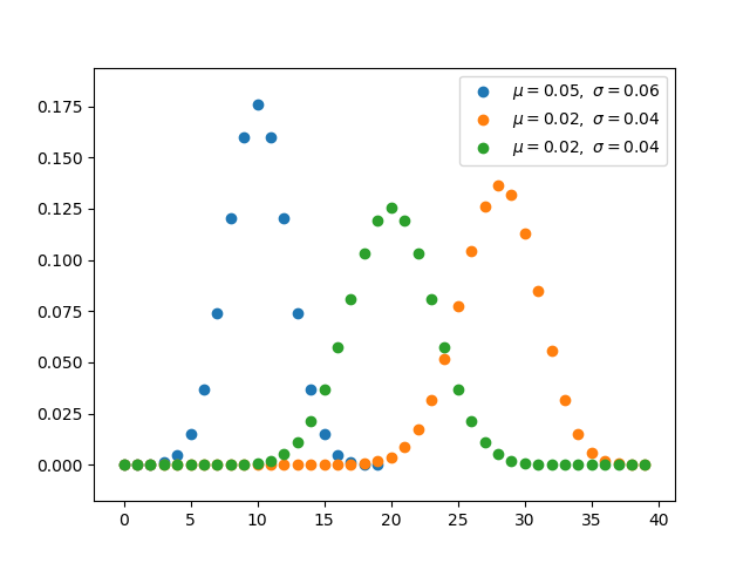
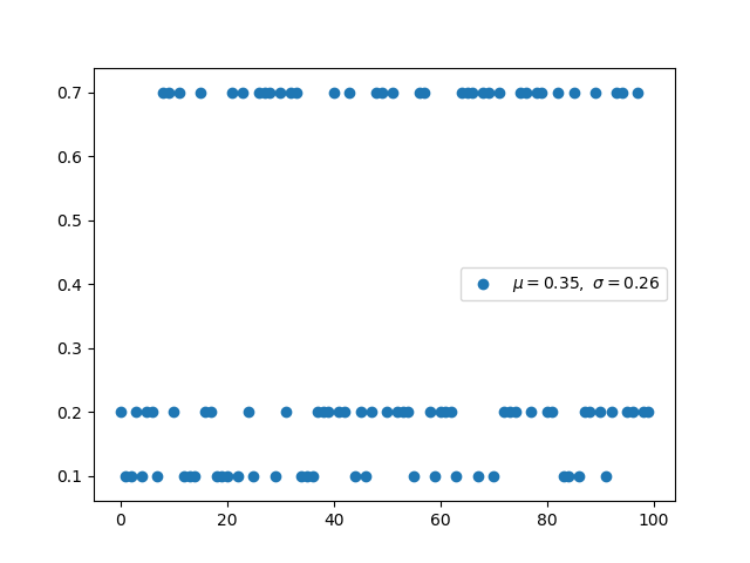
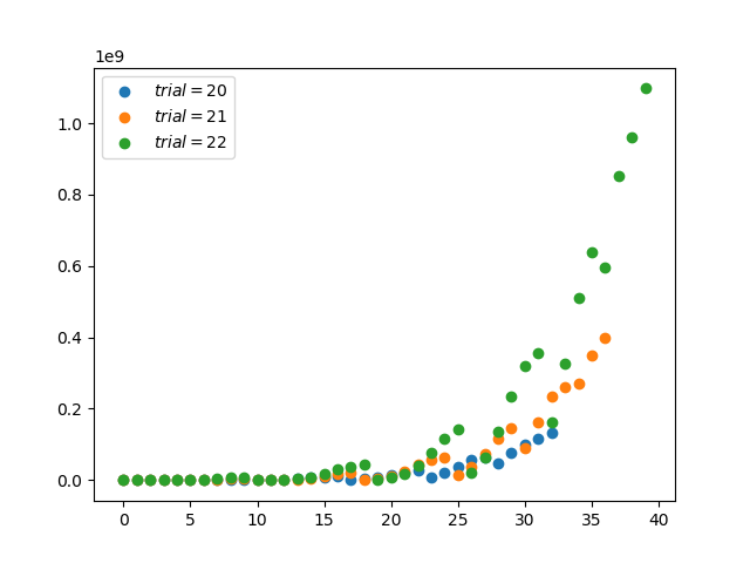
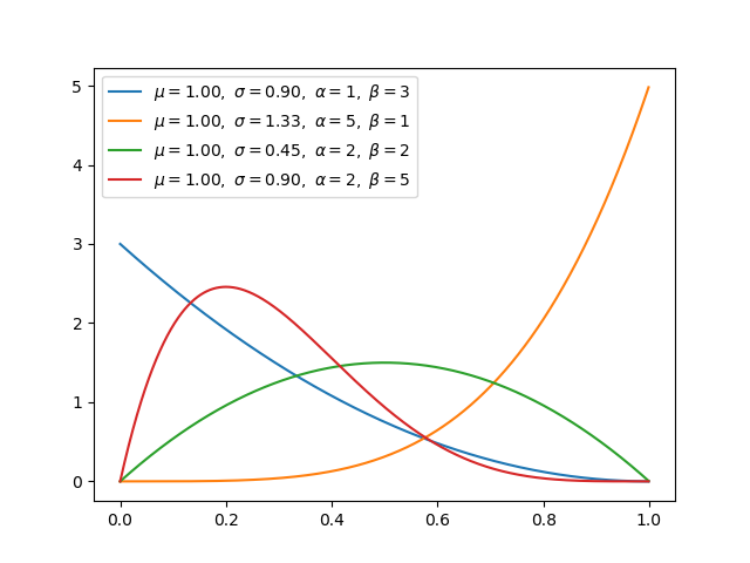
import numpy as np
from matplotlib import pyplot as plt
def exponential(x, lamb):
y = lamb * np.exp(-lamb * x)
return x, y, np.mean(y), np.std(y)
for lamb in [0.5, 1, 1.5]:
x = np.arange(0, 20, 0.01, dtype=np.float)
x, y, u, s = exponential(x, lamb=lamb)
plt.plot(x, y, label=r'$mu=%.2f, sigma=%.2f,'
r' lambda=%d$' % (u, s, lamb))
plt.legend()
plt.savefig('graph/exponential.png')
plt.show()
来源: 计算机视觉联盟